
Opzioni Avanzate di Personalizzazione
Questa pagina è destinata agli utenti avanzati con una certa conoscenza di HTML/CSS/JSON. Le impostazioni avanzate possono migliorare significativamente la flessibilità dell’adattamento, ma aumentano anche il rischio di scrivere configurazioni apparentemente corrette ma non funzionanti. Si consiglia di fare un backup prima della modifica.
Avvertenze Prima dell’Uso
- L’accesso si trova nelle Impostazioni sviluppatore.
- Eseguire il backup di “User Config” / “User Rules” prima di modificare, per evitare che errori di formattazione facciano ignorare la configurazione.
- Per la configurazione interna definitiva, fare riferimento a "Click to expand the final config" (campi, valori predefiniti, servizi disponibili).
Punti di Accesso e Priorità
Punti di accesso comuni (Impostazioni sviluppatore):
- Edit Full User Config: configurazione completa (include
rules, servizi di traduzione, stili, ecc.). - Edit User Rules: modifica solo dell’array
rules(questo accesso accetta solo array, non inserire{ "rules": [...] }). - Injected CSS: iniezione CSS globale.
Priorità (dal più alto al più basso): regole che corrispondono in rules > generalRule > configurazione predefinita interna.
Quando trova una regola (rule), unisce generalRule con la regola trovata, dando priorità ai campi in rule.
Inizio Rapido (necessità comuni)
1) Tradurre solo il corpo di un sito
{
"rules": [
{
"matches": ["example.com"],
"selectors": ["article", ".post-content"],
"excludeSelectors": ["nav", "footer", ".comment"]
}
]
}
2) Tradurre sempre / Mai tradurre
{
"translationUrlPattern": {
"matches": ["stackoverflow.com"],
"excludeMatches": ["www.google.com/mail/*"]
}
}
3) Usare servizi di traduzione diversi per siti diversi
{
"translationService": "google",
"translationServices": {
"deepl": {
"matches": ["sci-hub.se"]
}
}
}
4) Diversificare lo stile della traduzione in base al sito
{
"translationTheme": "none",
"translationThemePatterns": {
"underline": {
"matches": ["discord.com"]
}
}
}
5) Correggere lo stile della traduzione se causa problemi di layout
{
"rules": [
{
"matches": ["youtube.com"],
"globalStyles": {
"#video-title": "max-height:unset;"
}
}
]
}
6) Non mostrare nel pannello i servizi di traduzione non configurati
{
"showUnconfiguredTranslationServiceInPopup": false
}
Regole e Corrispondenze
Fusione delle Regole
generalRule: regola di base per tutti i siti.rules: regole specifiche per il sito, priorità più alta quando corrispondono.
I campi in rules possono utilizzare la maggior parte dei campi presenti in generalRule.
Formati comuni di matches
Il campo matches supporta stringhe o array:
- Dominio:
example.com - URL completo:
https://example.com/path/ - Wildcard:
https://*/*q=* - Tutti i siti:
*/*://*/*://*/* - File locali:
file://*
Nota: *.twitter.com corrisponde solo ai sottodomini, non al dominio principale twitter.com.
selectors / excludeSelectors
selectors: traduci solo gli elementi selezionati (sovrascrive la portata predefinita).excludeSelectors: escludi gli elementi selezionati dalla traduzione.
Se si desidera solo aggiungere/rimuovere elementi rispetto al comportamento originale, è preferibile usare .add / .remove (vedi sezione successiva).
Eredità e Modifiche Incrementali (.add / .remove)
Per campi array o oggetto, sono supportati .add / .remove per modifiche incrementali.
Consigliato per evitare di sovrascrivere le regole predefinite:
[
{
"id": "twitter",
"selectors.add": ["[data-testid='tweetText'] a"],
"excludeSelectors.add": ["header"]
}
]
Riferimento Rapido ai Campi Comuni (estratto)
Campi di corrispondenza:
matches/excludeMatchesselectorMatches/excludeSelectorMatches
Portata traduzione:
selectors/excludeSelectors/excludeTagsstayOriginalSelectors/stayOriginalTagsextraInlineSelectors/extraBlockSelectors
Stili e layout:
translationClasses: aggiunge classi extra alla traduzioneglobalStyles/globalAttributesinjectedCss/additionalInjectedCsswrapperPrefix/wrapperSuffixblockMinTextCount/blockMinWordCount
Tempi e versione mobile:
urlChangeDelay/observeUrlChangeisShowUserscriptPagePopup
Traduzioni tipo Chat GPT a flusso di messaggi
{
"matches": ["chat.openai.com"],
"excludeSelectors": [".markdown *"],
"aiRule": {
"streamingSelector": ".result-streaming.markdown",
"messageWrapperSelector": ".markdown",
"streamingChange": true
}
}
Per ulteriori dettagli sui campi, vedi l’appendice “Riferimento campi Rule” a fondo pagina.
Logica della corrispondenza matches (Versione breve)
- Solo dominio (senza
*e senza percorso): confronta solo l'hostname. - URL completo (senza
*): confronta protocollo + host + porta + percorso. - Con
*o protocollo omesso: corrisponde tramite regole wildcard (supporta http/https/file).
Esempi comuni:
twitter.com✅ corrispondehttps://twitter.com/home*.twitter.com✅ corrispondehttps://mobile.twitter.com, ❌ non corrispondehttps://twitter.comhttps://twitter.com/homecorrisponde solo a quell’URL precisotwitter.com/*corrisponde a tutti i percorsi sutwitter.com
Esempi di Adattamento Siti (prendendo Twitter come esempio)
Segue una regola interna per Twitter (estratto), per mostrare l’uso tipico di selectors, excludeSelectors e globalStyles:
[
{
"id": "twitter",
"matches": [
"twitter.com",
"mobile.twitter.com",
"tweetdeck.twitter.com",
"pro.twitter.com",
"https://platform.twitter.com/embed*"
],
"selectors": [
"[data-testid=\"tweetText\"]",
".tweet-text",
".js-quoted-tweet-text",
"[data-testid='card.layoutSmall.detail'] > div:nth-child(2)",
"[data-testid='developerBuiltCardContainer'] > div:nth-child(2)",
"[data-testid='card.layoutLarge.detail'] > div:nth-child(2)",
"[data-testid='cellInnerDiv'] div[data-testid='UserCell'] > div> div:nth-child(2)",
"[data-testid='UserDescription']",
"[data-testid='HoverCard'] div[dir=auto]",
"[data-testid='HoverCard'] span[dir=auto]",
"[data-testid='HoverCard'] [role='dialog'] div[dir=ltr]",
"[data-testid='birdwatch-pivot'] div[dir=ltr]"
],
"excludeSelectors": [
"[aria-describedby][role=button]",
"header",
"[data-testid='radioGroupplayback_rate'] div",
"[data-testid='userFollowIndicator']",
"[class='css-901oao r-14j79pv r-37j5jr r-n6v787 r-16dba41 r-1cwl3u0 r-bcqeeo r-qvutc0']",
"[class='css-175oi2r r-1wbh5a2 r-dnmrzs']"
],
"globalStyles": {
"[data-testid='card.layoutLarge.detail'] > div:nth-child(2)": "-webkit-line-clamp: unset;",
"[data-testid='card.layoutSmall.detail'] > div:nth-child(2)": "-webkit-line-clamp: unset;",
"[data-testid='tweetText']": "-webkit-line-clamp: unset;"
}
}
]
selectors: traduce solo il testo del tweet o contenuti principali evitando nickname/bottoni.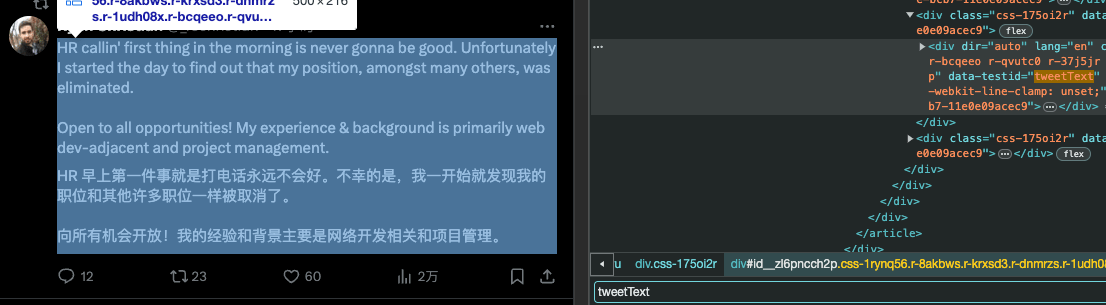
excludeSelectors: esclude bottoni, navigazione, e altri elementi interattivi.
globalStyles: rimuove i limiti di righe sul sito originale per evitare che la traduzione venga troncata.
Adattamento Siti Personalizzato
Si può riutilizzare una regola interna tramite id e modificarla incrementando/riducendo con .add/.remove:
[
{
"id": "twitter",
"selectors.remove": ["[data-testid=\"tweetText\"]"],
"selectors.add": ["[data-testid=\"tweetText\"] a"],
"excludeSelectors.add": ["header"],
"excludeSelectors.remove": []
}
]
Note:
idconsente di ereditare le regole interne evitando duplicazioni..add/.removemodifica incrementale degli array; altamente consigliata.
Id interni comuni (estratto):
isEbook: lettore epubisEbookBuilder: pagina generazione epub bilinguepdf: pagina confronto PDF bilingue
Regole interne complete:
https://github.com/immersive-translate/next-immersive-translate/blob/main/docs/buildin_config.json
Configurazione del Servizio di Traduzione
translationService: motore di traduzione predefinito.translationServices: configura servizi o sovrascrive quelli per sito.showUnconfiguredTranslationServiceInPopup: nasconde servizi non configurati.
Esempio (Tencent):
{
"translationService": "tencent",
"translationServices": {
"tencent": {
"secretId": "xxx",
"secretKey": "xxx",
"matches": ["twitter.com"],
"limit": 3,
"maxTextGroupLengthPerRequest": 25,
"maxTextLengthPerRequest": 1800,
"apiUrl": ""
}
}
}
Spiegazioni:
matches: per assegnare il servizio a uno o più siti.limit: throttling del servizio (richieste/secondo).maxTextGroupLengthPerRequest/maxTextLengthPerRequest: controlla la dimensione delle richieste.apiUrl: personalizza l’endpoint del servizio.
Impostazione Timeout della Richiesta (tempo massimo richiesta)
Puoi impostare il timeout (in ms) per ogni servizio; se usi servizi Pro puoi impostare anche proRequestTimeout.
{
"translationServices": {
"openai": {
"requestTimeout": 60000
},
"gemini": {
"proRequestTimeout": 90000
}
}
}
Note:
- Timeout troppo alto prolunga l’attesa; troppo basso rischia di fallire frequentemente.
- Il valore predefinito dipende dal servizio; consulta la configurazione finale.
proRequestTimeoutè attivo solo quandoproviderèpro(servizi premium).
Strategia Linguistica e Traduzione
Tradurre sempre / Mai tradurre per determinate lingue
{
"translationLanguagePattern": {
"matches": ["en"],
"excludeMatches": ["zh"]
}
}
Impostare lingua sorgente per specifici siti
{
"sourceLanguageUrlPattern": {
"en": {
"matches": ["*.google.com"]
}
}
}
Altre Impostazioni Globali Frequenti
Permettere il rendering di tag HTML
Abilita questa opzione per mostrare tag HTML nella traduzione:
{
"enableRenderHtmlTag": true
}
Stile e Tema della Traduzione
Stili supportati da translationTheme (consulta la configurazione finale aggiornata):
none, grey, dashed, dashedBorder, solidBorder, dotted, underline, mask, opacity,
paper, dividingLine, highlight, marker, marker2, blockquote, weakening, italic,
bold, thinDashed, nativeDotted, wavy, nativeDashed, nativeUnderline, background
Stile specifico per sito:
{
"translationThemePatterns": {
"highlight": {
"matches": ["discord.com"]
}
}
}
Parametri AI / Avanzati
Puoi aggiungere la seguente configurazione avanzata in Impostazioni sviluppatore -> Edit Full User Config:
Modalità di traduzione AI gratuita
L'estensione ora supporta un servizio gratuito di traduzione AI aggregata. Quando questa modalità è attiva, verrà data priorità al percorso di traduzione AI gratuita aggregata.
Limitazioni attuali:
- Il glossario AI non è ancora supportato
- I prompt AI personalizzati non sono ancora supportati
Per disattivare questa modalità e tornare alla precedente traduzione AI gratuita non aggregata, aggiungi:
{
"enableFreeModelMode": false
}
temperature
{
"translationServices": {
"openai": {
"temperature": 0.2
}
}
}
Personalizzazione header e body delle richieste
{
"translationServices": {
"claude": {
"headerConfigs": {
"anthropic-version": "2023-06-01",
"anthropic-dangerous-direct-browser-access": "true"
},
"bodyConfigs": {
"max_tokens": 2048
}
}
}
}
Come personalizzare impostazioni per modelli della serie Gemini
Poiché i modelli Gemini hanno impostazioni predefinite interne, si consiglia di usare modelsOverrides per sovrascriverle:
{
"translationServices": {
"gemini": {
"modelsOverrides": [
{
"models": ["gemini-2.5-flash", "gemini-2.5-flash-lite"],
"bodyConfigs": {
"temperature": 0.1
}
}
]
}
}
}
Nota: modelsOverrides funziona anche per altri servizi AI, sovrascrivendo i parametri per nome modello.
Applicare rigorosamente prompt personalizzati
Per ridurre i “deliri” delle AI, l’estensione verifica la qualità della traduzione confrontando il rapporto di token tra input e risposta. Se il rapporto è anomalo, il risultato viene rifiutato e si passa a un metodo alternativo. Se il tuo prompt serve per task non di traduzione (come parafrasi, espansione, ecc.), il rapporto token può essere anomalo. Abilita la modalità rigorosa per saltare questa verifica.
{
"translationServices": {
"claude": {
"strictPrompt": true
}
}
}
Prompt multi-lingua personalizzati (esempio parziale)
{
"translationServices": {
"openai": {
"langOverrides": [
{
"id": "auto2ja",
"systemPrompt": "あなたはプロの翻訳エンジンです。",
"prompt": "次のテキストを{{to}}に翻訳してください:\n\n<text>\n{{text}}\n</text>",
"multiplePrompt": "<yaml>\n{{yaml}}\n</yaml>",
"subtitlePrompt": "<yaml_subtitles>\n{{yaml}}\n</yaml_subtitles>"
}
]
}
}
}
Glossari & Traduzione Automatica
Ora è supportato il Glossario AI, valido solo per servizi AI.
Per default i servizi di machine translation non applicano il glossario (usano placeholder che possono compromettere la qualità), per forzarlo (non consigliato):
{
"enableMachineTranslateTerms": true
}
Ciclo Pulizia Cache
L’estensione svuota automaticamente la cache di traduzione ogni 30 giorni per evitare cali di performance.
{
"cacheMaxAgeDay": 30
}
Injected CSS & globalStyles
- Injected CSS: iniezione CSS globale, utile per correzioni a livello di pagina.
- globalStyles: override di stile a livello di regola per sito specifico.
Esempio Injected CSS:
.immersive-translate-target-wrapper img {
width: 16px;
height: 16px;
}
Debug e Problemi Comuni
*.twitter.comnon include il dominio principale; scrivere anchetwitter.com.selectorssovrascrive la portata default, usa preferibilmente.add/.remove.- Se scrivi
matchescomeexample.com/path, si comporta da wildcard. Verifica se vuoi l’URL completo. - Se una regola non funziona: controlla la configurazione finale dopo l’unione, poi ricarica la pagina.
- Virgole extra alla fine di un oggetto/array JSON fanno ignorare la configurazione.
Appendice: Riferimento Campi Rule
Segue il riferimento ai campi Rule (documentazione), copre i più usati; per lista aggiornata completa consulta la config finale.
Nota: per array e oggetti, .add / .remove funzionano per editing incrementale.
export interface Rule {
// Siti corrispondenti
id?: string; // ID regola interna, usare se si eredita una regola predefinita
matches?: string | string[]; // Questa regola vale solo per questi siti
excludeMatches?: string | string[]; // Esclude i siti indicati
selectorMatches?: string | string[]; // Seleziona per CSS senza definire URL
excludeSelectorMatches?: string | string[]; // Esclude selettori CSS
// Definire il campo di traduzione
selectors?: string | string[]; // Traduce solo gli elementi selezionati
excludeSelectors?: string | string[]; // Non tradurre questi elementi
excludeTags?: string | string[]; // Non tradurre questi tag
// Aggiunta di campi alla portata di traduzione
additionalSelectors?: string | string[]; // Selettori addizionali
additionalExcludeSelectors?: string | string[]; // Esclude elementi addizionali
additionalExcludeTags?: string | string[]; // Esclude tag addizionali (in alcune versioni deprecato)
// Mantenere originale
stayOriginalSelectors?: string | string[]; // Mantieni questi elementi in originale
stayOriginalTags?: string | string[]; // Mantieni questi tag in originale (es: code)
// Block o Inline
extraBlockSelectors?: string | string[]; // Considera come block
extraInlineSelectors?: string | string[]; // Considera come inline
inlineTags?: string | string[]; // Tag inline
preWhitespaceDetectedTags?: string | string[]; // Aggiunge newline per questi tag
// Stile traduzione
translationClasses?: string | string[]; // Classi extra per la traduzione
// Stili globali
globalStyles?: Record<string, string>; // Modifica CSS della pagina
globalAttributes?: Record<string, Record<string, string | null>>; // Modifica attributi degli elementi
// CSS iniettato
injectedCss?: string | string[]; // CSS iniettato
additionalInjectedCss?: string | string[]; // CSS addizionale
// Contestualizzazione
wrapperPrefix?: string; // Prefisso nell’area di traduzione
wrapperSuffix?: string; // Suffisso nell’area di traduzione
// Limiti per spezzare la traduzione su più righe
blockMinTextCount?: number; // Minimi caratteri per considerare blocco
blockMinWordCount?: number; // Minime parole per considerare blocco
// Limiti minimi per le entità traducibili
containerMinTextCount?: number; // Lungh. minima elementi smart
paragraphMinTextCount?: number; // Lungh. minima paragrafo
paragraphMinWordCount?: number; // Minime parole nel paragrafo
// Lunghezza max paragrafo per andare a capo
lineBreakMaxTextCount?: number; // Max caratteri prima di inserire a capo
// Tempi di attivazione
urlChangeDelay?: number; // Attesa post caricamento pagina
observeUrlChange?: boolean; // Ritraduci al cambio URL
// Mobile
isShowUserscriptPagePopup?: boolean; // Mostra popup su mobile
fingerCountToToggleTranslagePageWhenTouching?: number; // Deprecato
// AI streaming translation
aiRule?: {
streamingSelector: string; // Selettore per gli elementi in fase di traduzione
messageWrapperSelector: string; // Selettore del testo del messaggio
streamingChange: boolean; // True = aggiornamento incrementale
};
}