高级自定义选项
本页面向具备一定 HTML/CSS/JSON 基础的高级用户。高级配置可以显著提升适配能力,但也更容易写出“看似正确却不生效”的配置,建议先备份再编辑。
使用前提示
- 入口在 开发者设置。
- 编辑前先备份 User Config / User Rules,避免格式错误导致配置被忽略。
- 内置最终配置请以“Click to expand the final config”为准(字段、默认值、可用服务)。
入口与优先级
常用入口(开发者设置):
- Edit Full User Config:完整配置(含
rules、翻译服务、样式等)。 - Edit User Rules:只编辑
rules数组(此入口只接受数组,不要包{ "rules": [...] })。 - Injected CSS:全局 CSS 注入。
优先级(从高到低):命中的 rules > generalRule > 内置默认配置。
命中某条 rule 时,会将 generalRule 与该 rule 合并,以 rule 中字段为准。
快速开始(最常见需求)
1) 只翻译某网站的正文
{
"rules": [
{
"matches": ["example.com"],
"selectors": ["article", ".post-content"],
"excludeSelectors": ["nav", "footer", ".comment"]
}
]
}
2) 总是翻译 / 永不翻译
{
"translationUrlPattern": {
"matches": ["stackoverflow.com"],
"excludeMatches": ["www.google.com/mail/*"]
}
}
3) 不同站点使用不同翻译服务
{
"translationService": "google",
"translationServices": {
"deepl": {
"matches": ["sci-hub.se"]
}
}
}
4) 译文样式按站点区分
{
"translationTheme": "none",
"translationThemePatterns": {
"underline": {
"matches": ["discord.com"]
}
}
}
5) 译文导致样式错乱,用样式修复
{
"rules": [
{
"matches": ["youtube.com"],
"globalStyles": {
"#video-title": "max-height:unset;"
}
}
]
}
6) 不在面板里展示未配置的翻译服务
{
"showUnconfiguredTranslationServiceInPopup": false
}
规则与匹配
规则合并
generalRule:所有站点通用的规则基线。rules:站点级规则,命中后优先级最高。
rules 中的字段可以使用 generalRule 里的大多数字段。
matches 的常见形式
matches 支持字符串或数组:
- 域名:
example.com - 完整 URL:
https://example.com/path/ - 通配符:
https://*/*q=* - 匹配全部:
*/*://*/*://*/* - 本地文件:
file://*
注意:*.twitter.com 只匹配子域名,不匹配根域名 twitter.com。
selectors / excludeSelectors
selectors:仅翻译匹配到的元素(会覆盖默认范围)。excludeSelectors:排除不翻译的元素。
如果只是“在原范围上追加/移除”,请优先用 .add / .remove(见下一节)。
继承与增量修改(.add / .remove)
对数组或对象字段,支持 .add / .remove 作为“增量修改”。
建议使用它们来避免覆盖默认规则:
[
{
"id": "twitter",
"selectors.add": ["[data-testid='tweetText'] a"],
"excludeSelectors.add": ["header"]
}
]
常用字段速查(节选)
匹配相关:
matches/excludeMatchesselectorMatches/excludeSelectorMatches
翻译范围:
selectors/excludeSelectors/excludeTagsstayOriginalSelectors/stayOriginalTagsextraInlineSelectors/extraBlockSelectors
样式与布局:
translationClasses:为译文添加额外 classglobalStyles/globalAttributesinjectedCss/additionalInjectedCsswrapperPrefix/wrapperSuffixblockMinTextCount/blockMinWordCount
时机与移动端:
urlChangeDelay/observeUrlChangeisShowUserscriptPagePopup
类 GPT 页面流消息翻译
{
"matches": ["chat.openai.com"],
"excludeSelectors": [".markdown *"],
"aiRule": {
"streamingSelector": ".result-streaming.markdown",
"messageWrapperSelector": ".markdown",
"streamingChange": true
}
}
更多字段说明见文末「附录:Rule 字段参考」。
matches 匹配逻辑(简版说明)
- 纯域名(无
*且无路径):只比较 hostname。 - 完整 URL(无
*):比较协议 + 主机 + 端口 + 路径。 - 含
*或省略协议:按通配符规则匹配(默认支持 http/https/file)。
常见示例:
twitter.com✅ 命中https://twitter.com/home*.twitter.com✅ 命中https://mobile.twitter.com,❌ 不命中https://twitter.comhttps://twitter.com/home仅命中完全一致的 URLtwitter.com/*命中twitter.com下的所有路径
网站适配案例(以 Twitter 为例)
以下为内置 Twitter 规则(节选),用于说明 selectors / excludeSelectors / globalStyles 的典型用法:
[
{
"id": "twitter",
"matches": [
"twitter.com",
"mobile.twitter.com",
"tweetdeck.twitter.com",
"pro.twitter.com",
"https://platform.twitter.com/embed*"
],
"selectors": [
"[data-testid=\"tweetText\"]",
".tweet-text",
".js-quoted-tweet-text",
"[data-testid='card.layoutSmall.detail'] > div:nth-child(2)",
"[data-testid='developerBuiltCardContainer'] > div:nth-child(2)",
"[data-testid='card.layoutLarge.detail'] > div:nth-child(2)",
"[data-testid='cellInnerDiv'] div[data-testid='UserCell'] > div> div:nth-child(2)",
"[data-testid='UserDescription']",
"[data-testid='HoverCard'] div[dir=auto]",
"[data-testid='HoverCard'] span[dir=auto]",
"[data-testid='HoverCard'] [role='dialog'] div[dir=ltr]",
"[data-testid='birdwatch-pivot'] div[dir=ltr]"
],
"excludeSelectors": [
"[aria-describedby][role=button]",
"header",
"[data-testid='radioGroupplayback_rate'] div",
"[data-testid='userFollowIndicator']",
"[class='css-901oao r-14j79pv r-37j5jr r-n6v787 r-16dba41 r-1cwl3u0 r-bcqeeo r-qvutc0']",
"[class='css-175oi2r r-1wbh5a2 r-dnmrzs']"
],
"globalStyles": {
"[data-testid='card.layoutLarge.detail'] > div:nth-child(2)": "-webkit-line-clamp: unset;",
"[data-testid='card.layoutSmall.detail'] > div:nth-child(2)": "-webkit-line-clamp: unset;",
"[data-testid='tweetText']": "-webkit-line-clamp: unset;"
}
}
]
selectors:只翻译推文正文等核心内容,避免翻译昵称/按钮。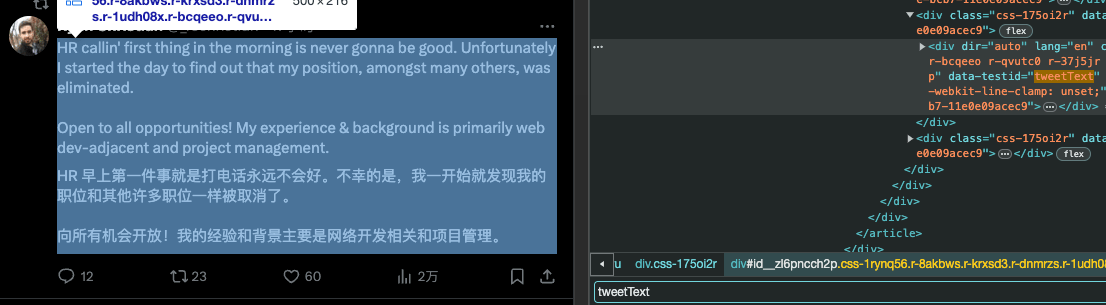
excludeSelectors:排除按钮、导航等交互元素。
globalStyles:取消原页面行数限制,防止译文被截断。
自定义网站适配
可以用 id 复用内置规则,并用 .add/.remove 做增量修改:
[
{
"id": "twitter",
"selectors.remove": ["[data-testid=\"tweetText\"]"],
"selectors.add": ["[data-testid=\"tweetText\"] a"],
"excludeSelectors.add": ["header"],
"excludeSelectors.remove": []
}
]
说明:
id可继承内置规则,避免重复写matches。.add/.remove对数组字段做增量修改,优先推荐。
常见内置 id(节选):
isEbook:epub 阅读器页面isEbookBuilder:生成 epub 双语书页面pdf:PDF 双语对照页面
完整内置规则:
https://github.com/immersive-translate/next-immersive-translate/blob/main/docs/buildin_config.json
翻译服务配置
translationService:默认翻译引擎。translationServices:服务配置与按站点覆写。showUnconfiguredTranslationServiceInPopup:隐藏未配置服务。
示例(以腾讯为例):
{
"translationService": "tencent",
"translationServices": {
"tencent": {
"secretId": "xxx",
"secretKey": "xxx",
"matches": ["twitter.com"],
"limit": 3,
"maxTextGroupLengthPerRequest": 25,
"maxTextLengthPerRequest": 1800,
"apiUrl": ""
}
}
}
说明:
matches用于指定该服务应用的网站。limit为服务限流(每秒请求数)。maxTextGroupLengthPerRequest/maxTextLengthPerRequest控制单次请求规模。apiUrl可自定义服务地址。
请求超时设置(最大请求时长)
可以按服务设置请求超时,单位为毫秒(ms)。若使用 Pro 服务,可单独设置 proRequestTimeout。
{
"translationServices": {
"openai": {
"requestTimeout": 60000
},
"gemini": {
"proRequestTimeout": 90000
}
}
}
提示:
- 超时时间过长会导致等待更久;过短则可能频繁超时失败。
- 默认值因服务而异,请以最终配置为准。
proRequestTimeout仅在provider为pro时生效(即会员翻译服务)。
语言与翻译策略
总是翻译 / 永不翻译的语言
{
"translationLanguagePattern": {
"matches": ["en"],
"excludeMatches": ["zh"]
}
}
为指定站点指定源语言
{
"sourceLanguageUrlPattern": {
"en": {
"matches": ["*.google.com"]
}
}
}
其他高频全局配置
允许渲染 HTML 标签
当需要让译文中保留并渲染 HTML 标签时可开启:
{
"enableRenderHtmlTag": true
}
译文样式与主题
translationTheme 支持的样式(以最终配置为准):
none, grey, dashed, dashedBorder, solidBorder, dotted, underline, mask, opacity,
paper, dividingLine, highlight, marker, marker2, blockquote, weakening, italic,
bold, thinDashed, nativeDotted, wavy, nativeDashed, nativeUnderline, background
按站点设置样式:
{
"translationThemePatterns": {
"highlight": {
"matches": ["discord.com"]
}
}
}
AI / 高级服务参数
temperature
{
"translationServices": {
"openai": {
"temperature": 0.2
}
}
}
自定义请求头与请求体
{
"translationServices": {
"claude": {
"headerConfigs": {
"anthropic-version": "2023-06-01",
"anthropic-dangerous-direct-browser-access": "true"
},
"bodyConfigs": {
"max_tokens": 2048
}
}
}
}
Gemini 系列模型用户如何自定义配置
由于 Gemini 系列模型有内置默认设置,若要覆盖这些内置设置,建议使用 modelsOverrides 进行按模型覆盖:
{
"translationServices": {
"gemini": {
"modelsOverrides": [
{
"models": ["gemini-2.5-flash", "gemini-2.5-flash-lite"],
"bodyConfigs": {
"temperature": 0.1
}
}
]
}
}
}
提示:modelsOverrides 也适用于其他 AI 服务,按模型名称命中后覆盖对应配置。
严格遵循自定义提示词
为减少大语言模型出现“幻觉”的问题,插件内置了翻译质量校验机制。系统会通过对比响应文本与请求文本的 Token 数量比例,来判断翻译结果的合理性。当该比例异常(过高或过低)时,当前结果会被视为无效并自动切换到备用翻译方案。 如果您的自定义提示词属于非翻译类任务(如扩写、润色或其他指令),可能会导致 Token 比例不符合常规标准。此时可开启严格模式,跳过比例校验。
{
"translationServices": {
"claude": {
"strictPrompt": true
}
}
}
自定义多语言提示词(节选示例)
{
"translationServices": {
"openai": {
"langOverrides": [
{
"id": "auto2ja",
"systemPrompt": "あなたはプロの翻訳エンジンです。",
"prompt": "次のテキストを{{to}}に翻訳してください:\n\n<text>\n{{text}}\n</text>",
"multiplePrompt": "<yaml>\n{{yaml}}\n</yaml>",
"subtitlePrompt": "<yaml_subtitles>\n{{yaml}}\n</yaml_subtitles>"
}
]
}
}
}
术语库与机器翻译
最新支持 AI 术语库 功能,仅 AI 翻译服务生效。
机器翻译默认不应用术语库(机器翻译通常采用占位符替换,可能导致质量下降),如需强制开启(不推荐):
{
"enableMachineTranslateTerms": true
}
缓存清理周期
插件默认 30 天自动清理翻译缓存,避免缓存过大导致性能下降。
{
"cacheMaxAgeDay": 30
}
Injected CSS 与 globalStyles
- Injected CSS:全局 CSS 注入,适合页面级统一修复。
- globalStyles:规则级样式覆盖,适合按站点修复。
Injected CSS 示例:
.immersive-translate-target-wrapper img {
width: 16px;
height: 16px;
}
排错与常见坑
*.twitter.com不包含根域名,请同时写twitter.com。selectors会覆盖默认翻译范围,优先用.add/.remove。matches写成example.com/path时会按通配符规则匹配,建议明确是否需要完整 URL。- 配置不生效时:先在最终配置里确认合并结果,再刷新页面。
- JSON 末尾多余逗号会导致配置被忽略。
附录:Rule 字段参考
以下为 Rule 字段参考(文档版),覆盖常用字段;完整/最新字段以最终配置为准。
提示:对数组或对象字段,可使用 .add / .remove 做增量修改,避免覆盖默认规则。
export interface Rule {
// 匹配网站
id?: string; // 内置规则 ID,复用内置规则时使用
matches?: string | string[]; // 该条 Rule 将仅匹配此处的网站
excludeMatches?: string | string[]; // 排除特定的网站
selectorMatches?: string | string[]; // 用选择器来匹配,而无需指定 URL
excludeSelectorMatches?: string | string[]; // 排除规则,同上
// 指定翻译范围
selectors?: string | string[]; // 仅翻译匹配到的元素
excludeSelectors?: string | string[]; // 排除元素,不翻译匹配的元素
excludeTags?: string | string[]; // 排除 Tag,不翻译匹配的 Tag
// 追加翻译范围(如无效请改用 selectors.add / selectors.remove)
additionalSelectors?: string | string[]; // 追加翻译范围
additionalExcludeSelectors?: string | string[]; // 追加排除元素
additionalExcludeTags?: string | string[]; // 追加排除 Tag(部分版本可能已废弃)
// 保持原样
stayOriginalSelectors?: string | string[]; // 匹配的元素将保持原样
stayOriginalTags?: string | string[]; // 匹配到的 Tag 将保持原样,比如 code
// Block or Inline
extraBlockSelectors?: string | string[]; // 匹配的元素作为 block
extraInlineSelectors?: string | string[]; // 匹配的元素作为 inline
inlineTags?: string | string[]; // 匹配的 Tag 作为 inline
preWhitespaceDetectedTags?: string | string[]; // 匹配的 Tag 自动换行
// 译文样式
translationClasses?: string | string[]; // 为译文添加额外 Class
// 全局样式
globalStyles?: Record<string, string>; // 修改页面样式
globalAttributes?: Record<string, Record<string, string | null>>; // 修改页面元素属性
// 嵌入样式
injectedCss?: string | string[]; // 嵌入 CSS
additionalInjectedCss?: string | string[]; // 追加 CSS
// 上下文
wrapperPrefix?: string; // 译文区域前缀
wrapperSuffix?: string; // 译文区域后缀
// 译文换行字数
blockMinTextCount?: number; // 译文作为 block 的最小字符数
blockMinWordCount?: number; // 译文作为 block 的最小单词数
// 内容可翻译的最小字数
containerMinTextCount?: number; // 智能识别时元素最少字符数
paragraphMinTextCount?: number; // 段落最小字符数
paragraphMinWordCount?: number; // 段落最小单词数
// 长段落强制换行字数
lineBreakMaxTextCount?: number; // 强制分行的段落最大字符数
// 启动翻译的时机
urlChangeDelay?: number; // 进入页面后延迟翻译
observeUrlChange?: boolean; // URL 变化时再次翻译
// 移动端
isShowUserscriptPagePopup?: boolean; // 在移动端展示页面浮窗
fingerCountToToggleTranslagePageWhenTouching?: number; // 已废弃
// AI streaming 翻译
aiRule?: {
streamingSelector: string; // 标记正在翻译元素的选择器
messageWrapperSelector: string; // 消息正文选择器
streamingChange: boolean; // 是否为增量更新
};
}