
PDF 是一种复杂的文件格式。
文本、图片、脚注、图表、公式、字体——它们都混合在同一个版面里,非线性的文件构成架构让所有的元素能够跨越不同平台呈现一致的效果,也给编辑增加了不少难度。
这都让 PDF 的翻译成为一种更高阶的“艺术”。
对大多数用户来说,BabelDOC 的默认设置已经足够好用:上传、翻译、导出,批量下载,一气呵成,用完即走。
但对于那些希望进一步掌控翻译过程的“高级玩家”——比如想固定术语译法、让模型有明确语气、控制版式细节的人来说,有一些实用技巧,值得认真研究一番。
它们分别是:自定义角色提示词、富文本翻译、字体自定义,以及术语/提取术语功能。
这些功能让 BabelDOC 从“可用”变得“可调”。
你可以让译文更统一,也可以让风格更符合领域语境。更重要的是——BabelDOC 把这些控制权都留给了你:
想要所见即所得,一切交给默认设置即可;想要更精细的翻译体验,也给了你自由探索的空间。
接下来,我们将依次介绍这四个功能的使用方法与应用场景,帮你在翻译专业文档时更高效、更精准。
自定义角色提示词 扮演一个翻译高手
不同类型的文档,对“翻译的语气”有着截然不同的要求
不同类型的文档,对“翻译的语气”有着截然不同的要求。
论文需要保持严谨,营销材料要自然流畅,专利翻译则更讲究术语与句法的一致,小说则更讲究用词丰富贴切与美感。
过去,BabelDOC 默认根据上下文进行自动判断;而现在,你可以亲自定义模型的“人格与语气”,让它更贴近你的翻译偏好。
这个功能源自沉浸式翻译的“角色提示词”系统,如今已完整引入 BabelDOC。

它允许用户在翻译开始前,为模型设置一个角色身份。例如:
- 学术译者:注重逻辑与句法对齐,常用于论文与研究报告
- 专业编辑:语言自然,适合商务报告与出版稿件
- 法律审校员:保持法律术语精确不变形,确保句式合法规范
- 技术写作者:优化句式清晰度,偏向可读性与信息传达
设置方法也很简单: 在上传原文 PDF 后,在翻译选项页面中找到**「自定义角色提示词」**,输入你想让模型扮演的角色描述。例如输入:
你是一名资深科技内容翻译,熟悉科技产品、创新文化与行业语言。翻译时需保持信息准确,同时追求叙事节奏与可读性,让复杂内容变得生动易懂。语气应专业又亲和,如同 WIRED 或 The Verge 的报道风格。
或者是扮演一个资深的小说翻译家:
你是一名经验丰富的科幻文学译者,擅长捕捉语气、意象与节奏。翻译时要在忠实原意的基础上保留文学张力,使文字具备画面感与世界构建感。语言应自然、富于想象力,仿佛原生创作。
亦或是一个专业的论文译者:
你是一名学术翻译专家,擅长不同领域的研究文体。你的译文应符合学术规范,逻辑清晰、术语准确、语气中立。目标是让论文读起来如同以目标语言撰写,足以刊登于学术期刊。
BabelDOC 会在翻译前将这一指令注入提示层
BabelDOC 会在翻译前将这一指令注入提示层,影响整份文档的语气与风格。
如果你经常在同一领域工作,可以将常用提示词保存为模板,随时调用。以此让每一份译文都更贴近原文的写作风格和使用场景。
富文本翻译:格式丰富 vs 成品稳定性的平衡
在 PDF 世界里,文字并不是纯文本。它往往带着颜色、字号、加粗、斜体、下划线,甚至是局部缩进、特殊符号等隐藏属性——这类内容统称为“富文本”。
BabelDOC 的新版本中加入了**「富文本翻译」**功能。 启用后,系统会在翻译时识别并保留这些格式信息,使译文在视觉上更贴近原文:标题突出,文字颜色,重点内容下划线,引用内容斜体…… 对于对版面要求较高的文档(如学术论文、技术报告、教学材料),这一功能能明显提升译文的结构感和可读性。

需要注意:富文本翻译对模型的指令理解和遵循能力要求较高
需要注意:富文本翻译对模型的指令理解和遵循能力要求较高。部分免费模型由于上下文窗口小,在执行时容易忽略样式信息,导致格式丢失或排版不稳。因此,这个功能默认关闭。
你可以选择“仅高级模型开启”模式,只在使用 DeepSeek,Qwen 等高级模型时启用这个功能,提升排版精度。
另外,PDF 的结构天生复杂,下划线与文字是分开记录的对象(例如“画了一条线”恰好和文字在相近的坐标上,而不是文字本身带有下划线),这就可能造成翻译后下划线位置与文字略有错位。 为此,BabelDOC 提供了一个过渡性选项:在设置中启用 「移除段落中非公式线条」,即可避免大多数错位问题,同时保留数学公式中的线条。
线条的翻译机制正在持续优化中,未来版本会以更底层的方式重构线条映射逻辑,进一步优化效果。
字体选择:让阅读质感更统一
字体决定了阅读的“质感”,行距、中心、视觉平衡,都会影响读者对文字的阅读观感,甚至是作者专业度的判断。
BabelDOC 在行业内提供领先的重排技术,通过灵活调整字体、字间距等,让译文保持良好的排版观感。在最新版中,我们又支持了自定义字体功能。
在外文翻译为中文的场景下,用户可以在上传后的设置画面中从自动、楷体、宋体、黑体几个字体中选择。
在不同的语言中使用统一字体家族,可以尽量避免混排、错排,或符号不一致等问题。
对于翻译为其他语种的情况,BabelDOC可以支持手写体(Script)、衬线字体(Serif)和非衬线字体(Sans-serif)。
字体并不只关系到美观,也和使用场景密切相关
字体并不只关系到美观,也和使用场景密切相关。
如果你的文档主要用于长篇阅读、高分辨率屏幕或打印输出,推荐使用衬线体(如宋体、NotoSerif)——衬线能在高分辨率条件下提供更好的阅读节奏与行距引导。 而对于常规屏幕浏览的场景,无衬线体(如黑体、NotoSans)更适合:线条简洁、抗锯齿性能更好,在低 ppi 屏幕上依然清晰。
这里可以透露一下目前 BabelDOC选择的译文字体——
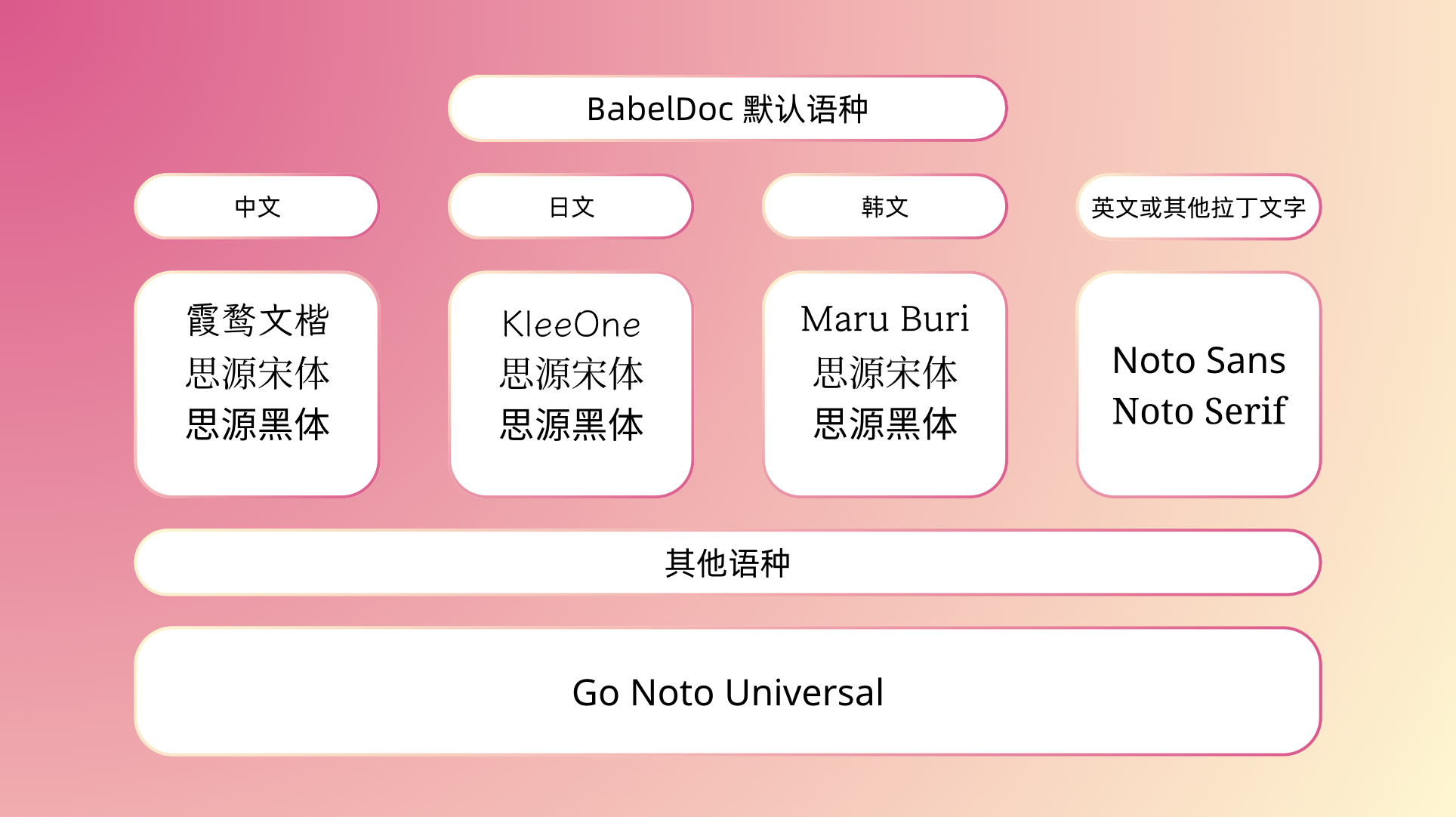
对中文而言,当您选择楷体时,系统会使用霞鹜文楷,宋体/黑体则使用思源宋体 / 思源黑体。

对于韩语,当您选楷体时,我们会使用MaruBuri。对于日语,您选择楷体时,我们会使用KleeOne。日语和韩语的宋体/黑体会使用对应语言的思源宋体 / 思源黑体。
英语及其他拉丁语系:NotoSans / NotoSerif(斜体则使用对应 Italic 字体)
上述字体都没有的字符则会使用Go Noto Universal字体(无衬线体/黑体风格)兜底
简言之,这个功能让你在翻译完成后,译文能以统一、规范的面貌呈现,大幅减少进一步处理所需要的时间,可读性也有保障。
AW补充:我们注意到了字体和翻译目标语种对应关系的问题,下一个版本会做出调整。
术语库与自动提取术语:让专业词汇更统一
在处理学术论文、法律文档或技术报告时
在处理学术论文、法律文档或技术报告时,术语的一致性往往比句子本身更重要。
同一个英文词汇,如果在不同段落被译成不同版本,影响阅读体验事小,专业表达失准事大。
为此,BabelDOC 新增了 术语库与自动提取术语 功能。
它能在两个层面协同工作,帮助模型更稳定地处理专业词汇:
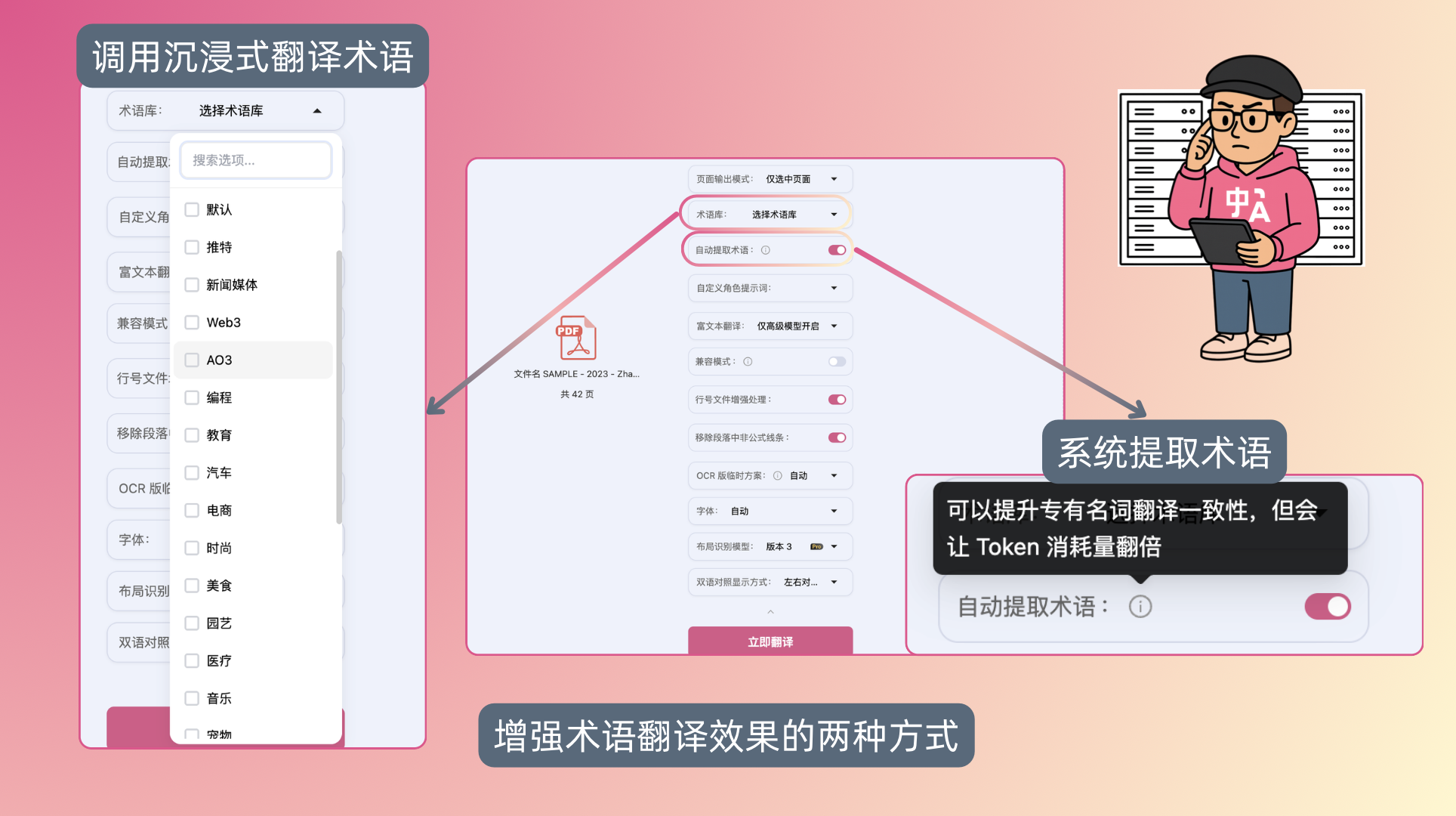
- 术语库调用:你可以直接使用沉浸式翻译的官方术语库,也可以上传自己维护的术语文件。上传后,系统会在翻译过程中对照术语表进行替换,确保整份文档的固定译法一致。对于经常批量翻译同一类型文档的用户(如专利、研究报告、行业白皮书),这一机制能显著降低后期人工校对成本。一次添加,永久受益。创建自建术语库的方法可以看这篇文章:一次「史诗级更新」:三大功能,让翻译工具真正服务于你。
- 术语自动提取:BabelDOC 会在翻译前扫描文档,识别高频专业词汇,并在翻译过程中自动锁定其译法。这一过程是实时进行的,无需额外设置,系统会基于上下文计算确定最可能的专业译名并保持统一。
术语库调用会增加 Token 消耗,但对于对准确性要求较高的用户而言,这是一种值得的投入。有了这层支持,翻译大型文档时的术语一致性大幅提升。
它让 BabelDOC 从单纯的翻译工具,距离一个可管理可控制的系统更进一步。
过去几个版本中,BabelDOC 在 PDF 的解构、翻译、重建与呈现环节都有了不小的突破。产品的每一次迭代,都离不开用户社区的反馈和建议。
我们也清楚,BabelDOC 还有许多值得继续完善的地方。例如,当前仍无法对 OCR 扫描版 PDF(即以图片形式保存的文档)进行完整的解析和翻译。这是我们正在重点攻克的方向之一。
接下来,BabelDOC 的开发重点仍会围绕“质量更优,格式支持更广,使用更便捷”的目标推进。
有了来自用户的真实反馈,BabelDOC 才能不断向前。
期待下次更新能为大家带来更多激动人心的新功能,新体验!


