
从 2023 年开始,短短两年时间,大家对 AI 的使用态度早已发生了变化。
写完英文邮件,整理完一份合同,看一篇外文报告,第一反应不再是“自己硬啃”,而是会习惯丢给 AI(或者沉浸式翻译)。
效率,在飞速提升。语言门槛,也在不断降低。
但与此同时一个顾虑也越来越常见:
“我的内容,有客户信息,有银行账号,甚至有密码。我真的应该通通交给 AI 吗?”
作为 AI 工具团队,沉浸式翻译深刻感受到这种矛盾,也意识到必须有人出手解决这个问题。
作为 AI 大模型工作的“原料”,大部分的文本信息在处理之前,其实处于一种“裸奔”的状态。
只要用户不进行任何加密、脱敏措施,直接把内容发给云端的大模型,里面包含的所有信息——大到客户银行卡号密码,小到你收到的一条验证码——理论上都有机会被大模型记录和保存下来。
拿去干嘛用?也许是用作大模型训练的语料,也许被当做缓存等着下次被“命中”。
你的隐私信息,会不会出现在隔壁老王的 AI 对话中?
谁也不知道。
这就是为什么许多用户和单位要求“涉密内容不上 AI”的根本原因:你的信息没加密脱敏,哪怕效率低点,也不能冒这个风险。

很多技术团队为了解决这个问题,首先考虑的是本地化部署。顾名思义,就是搭建强大(且昂贵)的本地系统,安装上大模型,并且只允许内部访问。
“我的数据只在我家里,这才安全”。
这么做当然很好,但也牺牲了很多。
- 本地部署服务器跑大模型,不管是部署还是运维成本都很高,需要专人进行长期投入
- 本地算力再怎么提升也是有限的,很难持续跟上云端最新最强的大模型
对于不差钱的大公司,这也许能通过堆资源解决,但无数中小团队和个人用户,这么做未免门槛过高。
沉浸式翻译选择的是另一条路径:
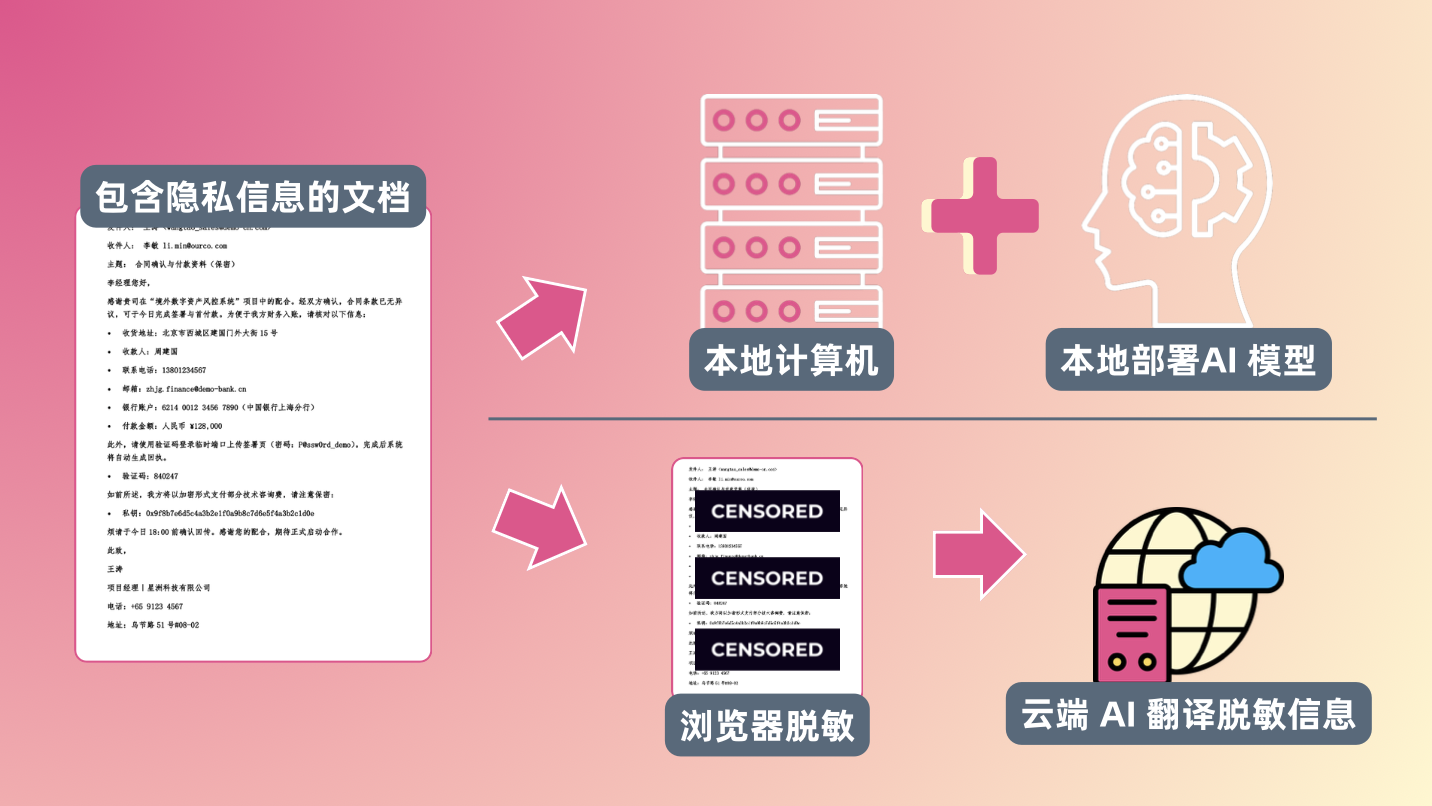
- 如果说信息在上传到云端前都不安全,那我们把敏感的信息都脱敏加密了再喂给 AI 是不是好多了?
- 如果脱敏加密在云端不够安全,能不能在本地完成?
- 最后,在本地把云端翻译好的文本,加上还原的敏感信息,组合成译文。
这不就两全其美了吗?
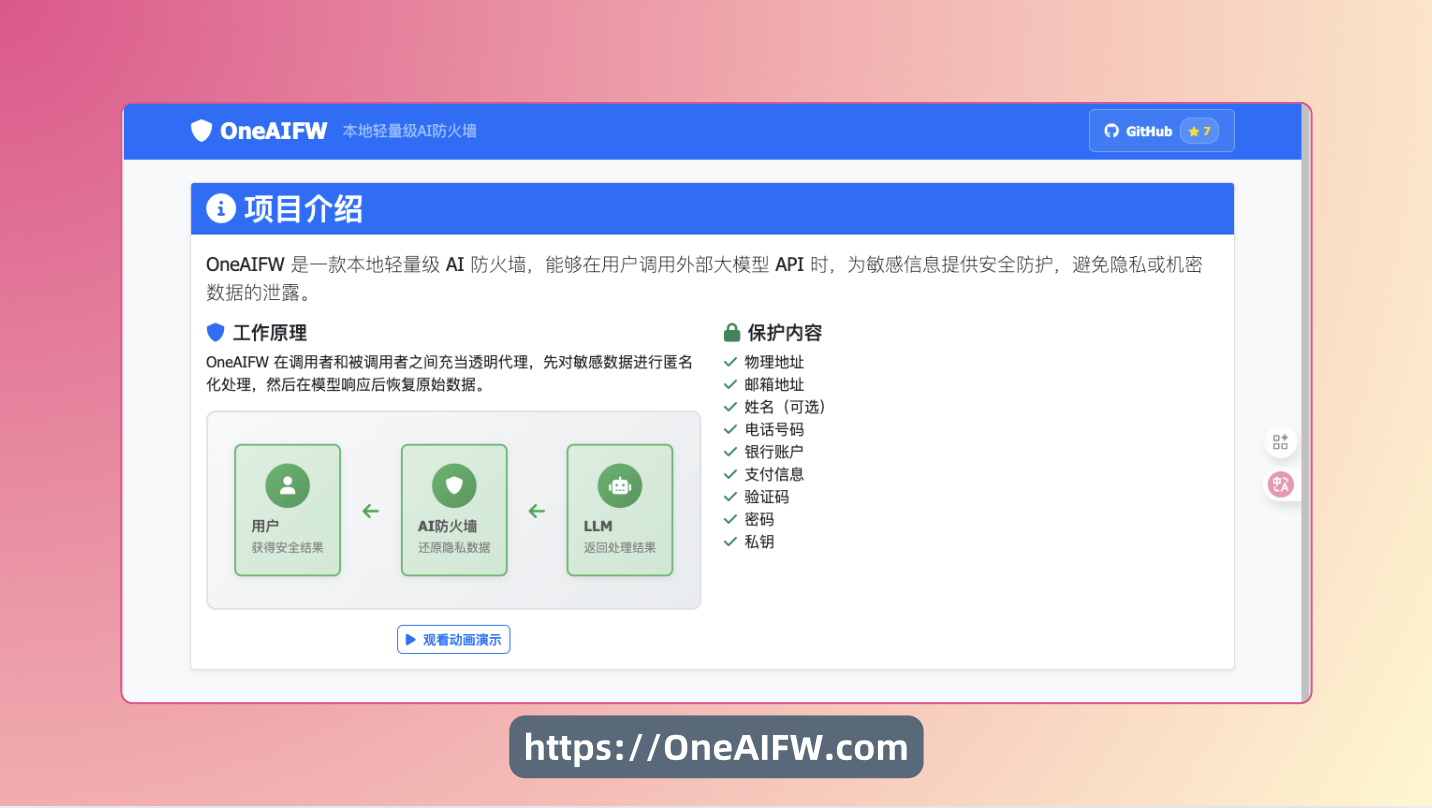
今天,我们隆重介绍 AI 翻译内容隐私保护解决方案——
OneAIFW
在我们有限的了解范围内,这是行业内目前还不多见的专门针对“翻译场景下的隐私保护”给出完整产品方案的尝试。
而且,这套能力是开源的
OneAIFW 目前在 GitHub 上,通过 MIT 协议开源
细节摊在阳光下,个人开发者和企业都可以基于此做集成和拓展。
让 AI 翻译的信任黑盒,再少一个。
为了让大家更直观地理解这件事,我们专门搭了一个 OneAIFW 的网站。 你可以把一段真实场景的文本粘进去,现场看一眼这个功能是怎么工作的。
首先,在你电脑里,把敏感信息“打码”
这个过程全部发生在浏览器本地。在页面背后,有一个跑在本地的非联网“小模型”,会自动扫描你输入的内容,识别出里面的关键信息,并给它们重新编码,替换成匿名文本。
目前可以被自动脱敏的内容主要包括:
- 姓名
- 物理地址
- 电子邮箱地址
- 电话号码
- 银行账户
- 支付信息
- 验证码
- 密码
- 私钥
对你来说,就是把一段原始文本粘进去,页面会立刻给这些字段“打马赛克”,改成特定的加密类型文字。
发给云端的,是“打码之后”的内容
接下来,才轮到云端出场。
真正发给云端 AI 模型的,只是这份已经被脱敏后的文本(即下图右侧的文本)——

(图中信息为虚拟,如有雷同纯属巧合??)
模型看到的是一段可以理解上下文的内容,但接触不到你的真实隐私数据。 它能做的事情只有一件:根据上下文,把这段打码后的文本翻译好。
回到本地,自动还原成一份“完整译文”
翻译结果回来后,浏览器会在本地再做一次事:把之前锁起来的那些真实信息,按规则填回去,生成你真正要看的那份完整译文。
整个过程里:
- 云端 AI 只能看到“打码版本”;
- 包含所有完整信息的版本,只存在于你的浏览器中;
- 作为用户,你几乎不用做任何额外操作,只是照常完成了一次翻译。
换句话说,沉浸式翻译带给你的翻译,依然快且准。
但是,不该被外人看到的隐私,现在多了一道锁。
就像装修房子,你的隐私放在保险柜里,只有你能在原地打开,而装修队只能碰除了保险柜以外的地方。
等房子装修好了,再把敏感信息,连同焕然一新的房子,交到你手里。

坦白说,OneAIFW 还是很年轻。
年纪小(版本号低),能力刚开局,问题肯定不少,所以还在「beta」测试阶段。目前,这套敏感信息脱敏能力:
- 只支持中文和英文内容的翻译过程保护;
- 目前本地小模型的识别能力还不够完善,但我们正在不断优化和提升;
- 已接入的产品范围有限:目前支持:网页翻译、普通文档翻译。其他产品(包括 BabelDOC 和移动 App)暂时还无法调用这套能力。
如果你想在沉浸式翻译里体验这项功能,首先请升级到最新的 V1.23.3 或更高版本插件。
(如果你的插件商店提供的是旧版本,可以考虑安装 Preview 版)
然后,在插件设置中打开敏感信息脱敏功能,路径是:
沉浸式翻译面板 → 设置 → 进阶设置 → 隐私模式(beta) → 敏感信息脱敏 → 选择「内置」
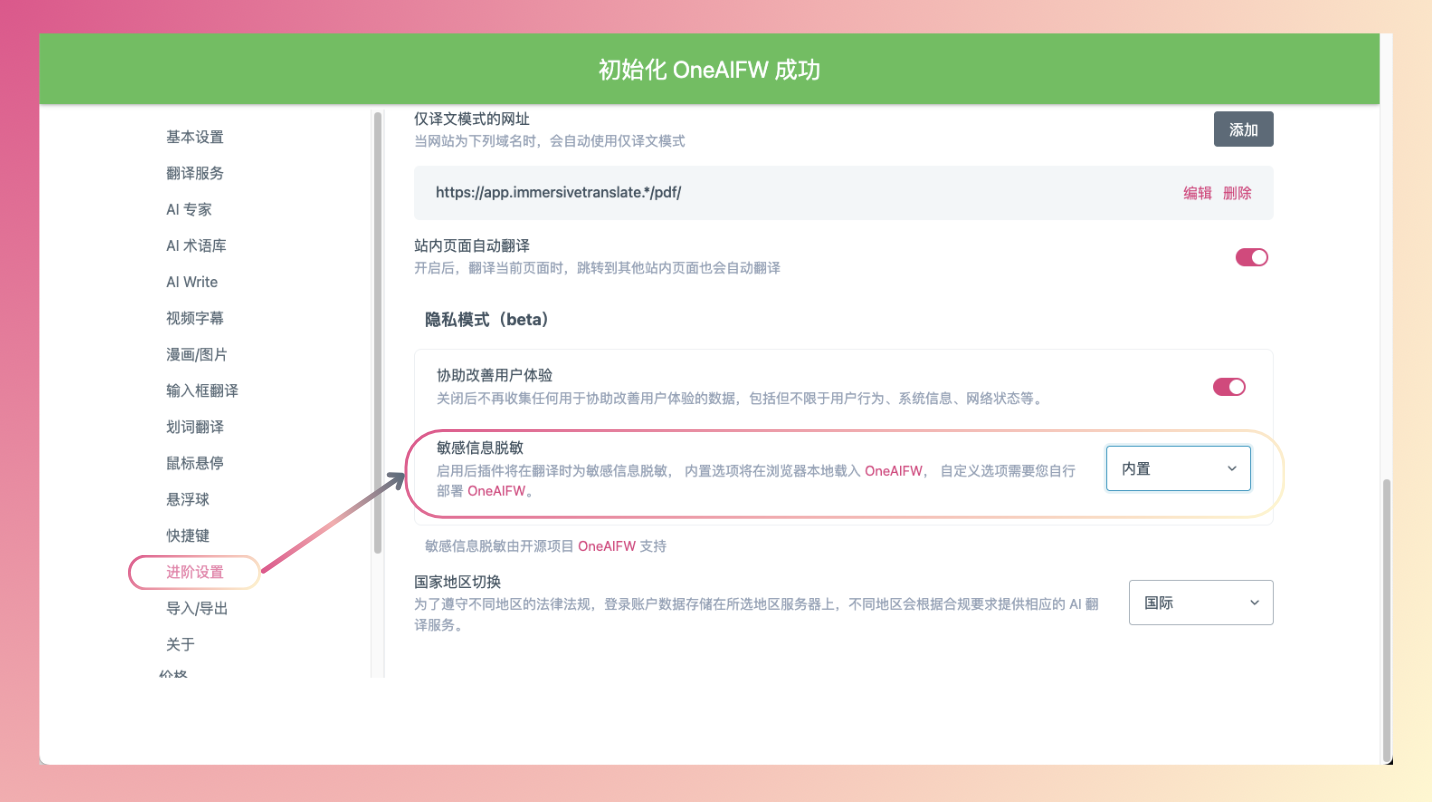
激活初始化后顶部会有横幅提示??

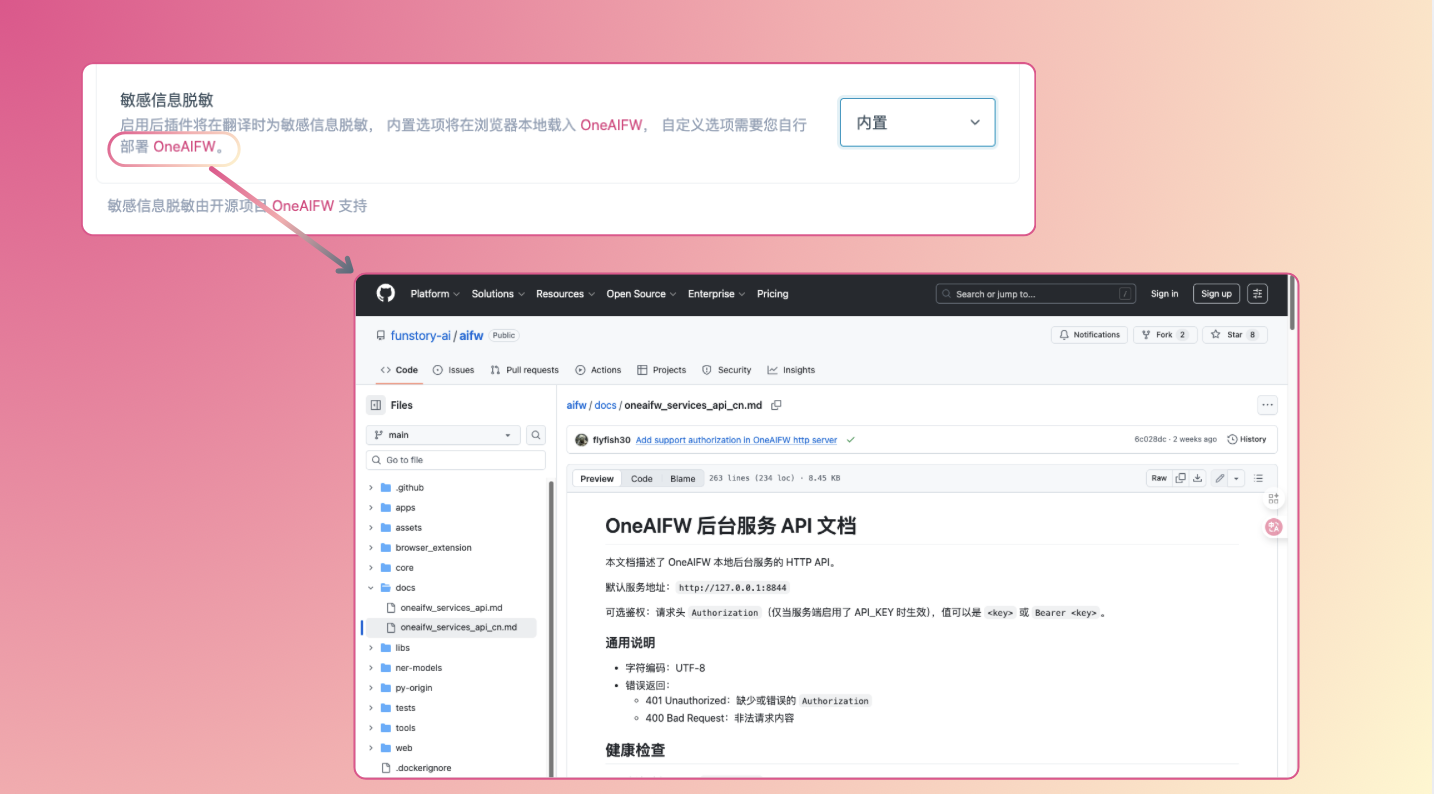
对动手能力比较强的朋友,我们也保留了一条“折腾路线”:
可以直接点击 OneAIFW 的 GitHub 链接,自己研究如何把这个小模型部署到本地,按自己的环境、需求做更细的集成。
接下来,我们会重点在几件事上持续迭代:
- 提高识别的 精确性与稳定性,特别是地址等复杂字段;
- 扩展 多语种支持,不只服务中英文;
- 拓展到更多 产品和场景。
也非常欢迎你在评论区留下对这个功能的真实想法和期待:你怎么用、有哪些顾虑、希望它做到什么程度,都会直接影响它接下来的走向。
沉浸式翻译一直致力于用好 AI 模型,服务翻译这一件事。
这次做 OneAIFW,其实就是承认一句实话:在大模型已经铺开的时代,能不能放心用 AI 是一个值得解决的问题。
本地识别、本地上锁、云端翻译、本地还原,这套能力刚起步,现在还不完美,但至少是个开始——
让隐私保护不只停留于隐私协议那几段长篇大论中。
我们接下来会继续沿着这条路往前走:一边提可用性,一边把“安全感”做得更实在一点。
希望能迎来你 100% 安心托付的一天。

和产品负责人 Parker 与 AW 聊聊 OneAIFW
Q:为什么说敏感信息脱敏是 AI 时代的刚需?
因为几乎所有文字类的 AI 应用,都不可避免地接触真实数据。 当大模型变成日常工具,数据和隐私保护就不再是附加条件,而是必须从底层去解决的问题。
Q:为什么 OneAIFW 选择 MIT 开源协议?
为了让更多人能用得起、用得快。 MIT 协议几乎没有使用门槛,只要求保留署名,让个人和企业都能放心集成。
Q:为什么 OneAIFW 坚持开源?
涉及安全的系统,最怕“看不见”。 我们开源的核心理由,就是让所有人都能检查代码、审视逻辑、发现问题——
“君子坦荡荡”,这句话在 AI 安全领域同样适用。
Q:OneAIFW 未来的方向是什么?
我们希望它不仅是一款产品,而能成为一种“基础设施”——一个任何团队都能调用的敏感信息脱敏加密工具。只要有需要保护隐私的文本处理场景,都可以直接用上,而不用重新造一遍轮子。
同时,我们真诚欢迎更多开发者、研究者和使用者加入进来。不论是改进算法、优化识别率,还是提出更实际的场景需求、反馈问题、撰写文档,都能让这个项目更稳、更有生命力。
感谢所有在 OneAIFW 项目开发过程中给予支持与灵感的同事、开源社区、开发者和用户。每一次讨论、每一行代码、每一次反馈,都是推动我们不断前进的重要力量


