
如今的大语言模型(LLM),如 ChatGPT, Gemini, DeepSeek 等性能已经非常强大了,作为翻译工具完全足够,但我们会发现,当用 LLM 翻译一些篇幅较长的文章、论文、报告时,会出现一些「不对劲」之处:
一些术语前后不一致,一些姓名和名词的翻译上下不一样,有的地方英文单词的缩写进行了翻译,有的却还是英文缩写……
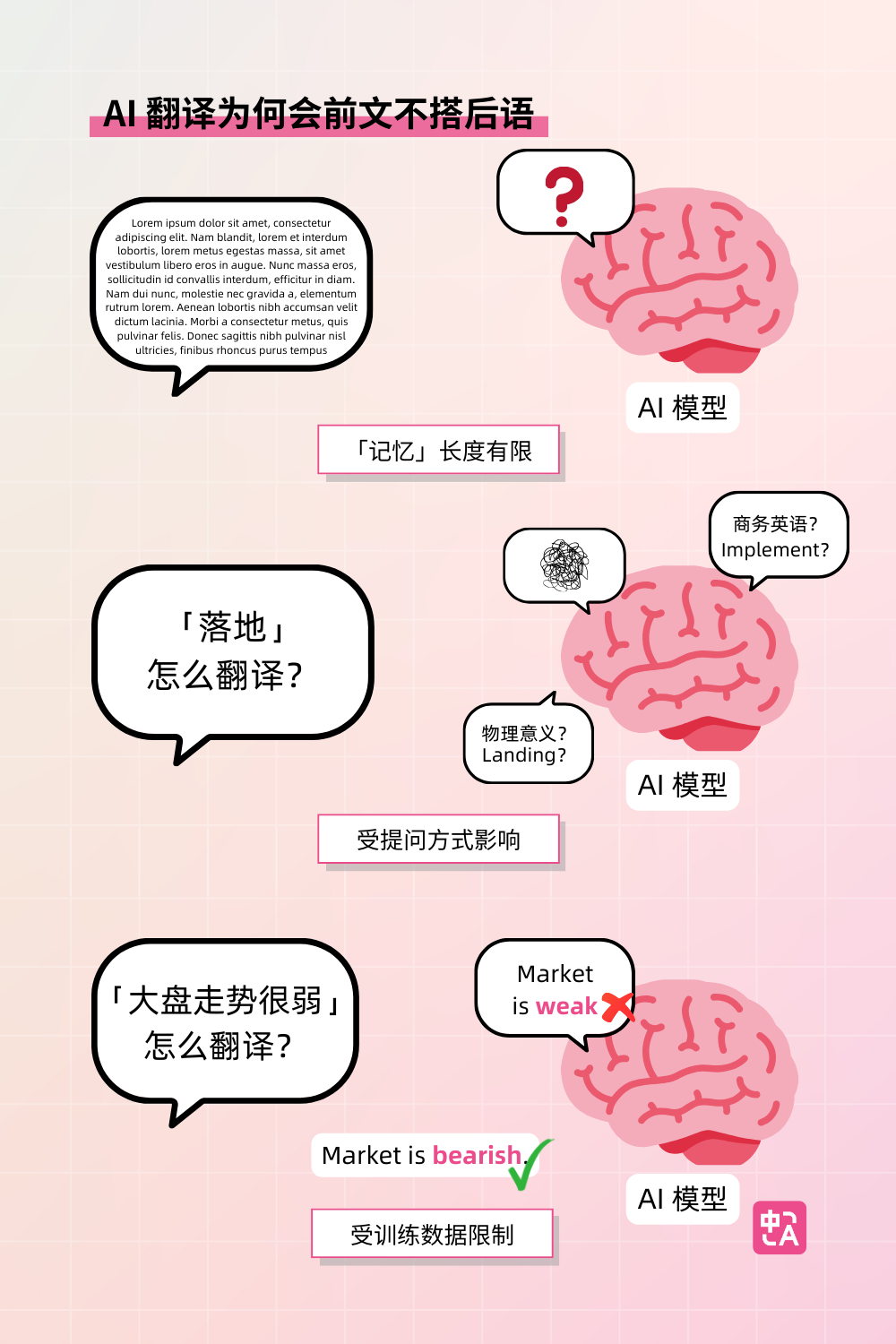
其实这是 LLM 底层功能的限制造成的。我们可以把 LLM 想象成人的大脑,需要接收相对精确的指令(也就我们常说的 prompt),捕捉核心信息,然后对文字进行阅读记忆,最后匹配对应的语种翻译输出。
而译文「前后不一致」的问题,往往源于上面的步骤中出现了三个问题:
1. 「记忆」长度有限:LLM 的记忆当然很强
- **「记忆」长度有限:**LLM 的记忆当然很强,但它有个致命弱点:会优先关注最近输入的内容。如果对话长度太长,较早接收的信息可能被逐渐“遗忘”,导致回答偏离主题,或者导致翻译过程中上下文不一致。这在技术上叫做“注意力衰减”。
- **容易受提问方式影响:**如果 prompt 指令有歧义,或者关键词不够突出,LLM 可能无法捕捉核心需求。例如,「落地」这个词在物理上翻译成 landing,在商务中一般翻译成 implement,类似这种一词多含义的情况,如果不能通过 prompt 进行精准调试,就容易在超长的文本翻译中出现前文不搭后语。
- **训练数据特征:**模型依赖海量文本,当遇到训练数据中罕见的问题组合时,LLM 会「偷懒」倾向于输出统计概率最高的回答,而不是严格遵循逻辑。
作为长期专注于 AI 翻译的产品,沉浸式翻译早已注意到 LLM 在这方面的局限性,并开发了「AI 智能上下文翻译」功能,对 LLM 的局限性和潜能扬长避短,从而大幅提升长篇和专业内容翻译的准确性。
具体是怎么实现的呢?本着开源精神,沉浸式翻译工程师团队透露:
智能上下文功能对整页的内容提取摘要,並在翻译不同段落时带上摘要信息,从而优化短句或术语在各自段落翻译时出错的问题。
让我们来看看效果:

更多细节
- 智能上下文功能支持网页长篇文字内容、电子书、PDF
- 智能上下文功能支持网页长篇文字内容、电子书、PDF 翻译和双语字幕。
- AI 翻译专家也可支持智能上下文。
- 目前为实验功能,仅 Pro会员 可用,仅可用于部分支持的模型,如 OpenAI,Gemini,Claude和 DeepSeek。
如果你购买了 Pro 会员,一定要尝试这一新功能

如果你购买了 Pro 会员,一定要尝试这一新功能,体验翻译质量的明显提升。
开启方式:设置 → 翻译服务 → OpenAI / Claude / DeepSeek / Gemini → 去修改 →启用 AI 智能上下文翻译。
为什么选择沉浸式翻译
沉浸式翻译,作为一款以用户需求为核心驱动的 AI 翻译工具,成功帮助超过 1000 万用户打破语言壁垒,畅享全球信息。在2024年年底,沉浸式翻译还被谷歌 Chrome 应用商店评选为 2024 年度全球最佳扩展。从独立开发项目到广受全球用户欢迎,沉浸式翻译仅用两年时间就实现了这一飞跃。
网页版和移动端入口如下,点击即可进入!



