
「太快了」。这是很多朋友在谈到眼下的 AI 发展速度时的感受。
今天看到了一篇新论文,感觉会有点用,赶紧收藏下来;
明天冒出了一个新的模型,赶紧去排队申请试用;
后天又有了个新的文生图/文生视频工具火遍全球,又迫不及待地注册账号;
一边抱怨排队人太多,一边等着生成图片或视频的“抽卡”结果……
跟风容易,消化难;看热闹快,转化成自己的工作流慢。
所以,这一期我们想换个角度,不只是“追热点”,而是带来五个更“底层”的启发:
- 来自 DeepMind 的 Step-Back 提示法,让 AI 学会退一步思考;
- 一份由哥大与 MIT 联合提出的密度链摘要技巧(CoD),教你如何逼 AI 写出“像资深编辑一样”的高密度总结;
- 一个收录百种思维模型的“认知武器库”;
- Google 官方的 Nano Banana 提示指南;
- 以及一本 AI 生图“魔法书”。
希望这些能帮你建立起AI 时代的思维方式和操作习惯,把前沿成果转化成自己的生产力与创造力。
搭配沉浸式翻译,你能第一时间用中文语境去吸收、内化、试验,而不是把灵感搁置在收藏夹里落灰。
Nano Banana 官方文生图手册
像写摄影说明书一样写提示词
最近刷屏的 Nano Banana,其实背后就是 Gemini 2.5 Flash Image ——Google 最新的多模态图像生成模型。
Google 也贴心地放出了一份官方“写提示词手册”,告诉我们:**好图的关键不在堆关键词,而在写故事,**要把提示词写成摄影师或设计师的说明,要描述场景,而不是只说几个词。举个例子:
- 普通写法:“A fantasy armor”(一副幻想风格的盔甲)
- 官方推荐写法:“Ornate elven plate armor, etched with silver leaf patterns, with a high collar and pauldrons shaped like falcon wings.”(一副华丽的精灵板甲,镶嵌着银色叶纹,高领设计,肩甲形似猎鹰的双翼。)
后者才像给工作室的拍摄 brief。
比如说——
- 照片级写实 想要生成写实照片
- 照片级写实 想要生成写实照片,就要像摄影师一样写:镜头类型、光线、氛围缺一不可。例:一位中国陶艺家在夕阳下的工作室里,85mm 镜头捕捉他检查新烧制的紫砂壶,背景虚化,氛围宁静而专注。

- 插画与贴纸 如果要做轻量素材,指定风格和背景:例:一只戴竹帽、啃竹叶的小熊猫卡通贴纸,干净线条+白色背景。

- 产品与电商图 电商场景更讲究布光和角度:例:一只黑色陶瓷咖啡杯,三点布光,45 度俯拍,蒸汽细节清晰。

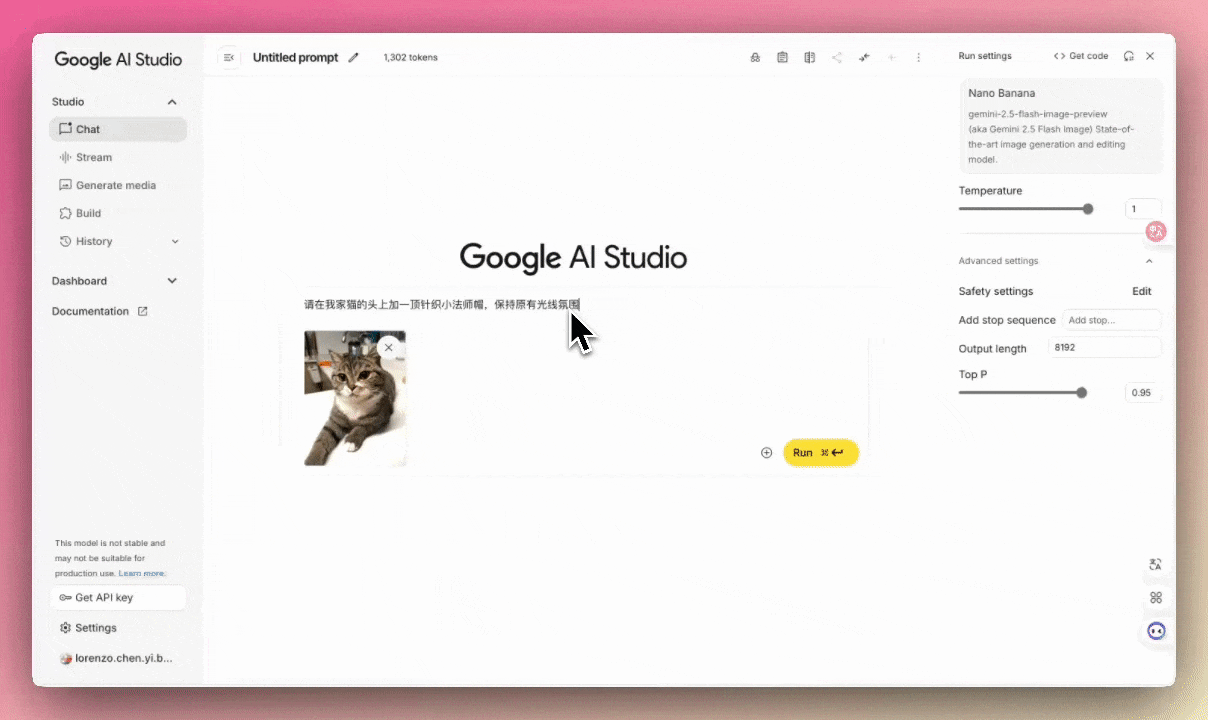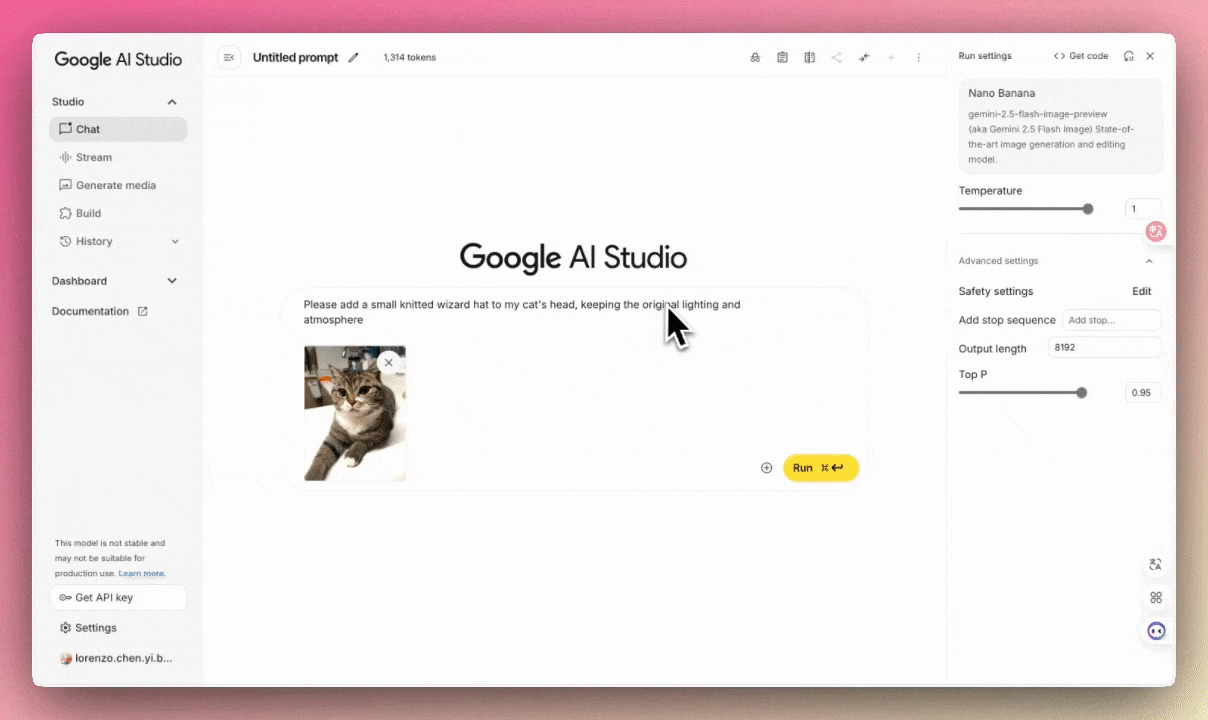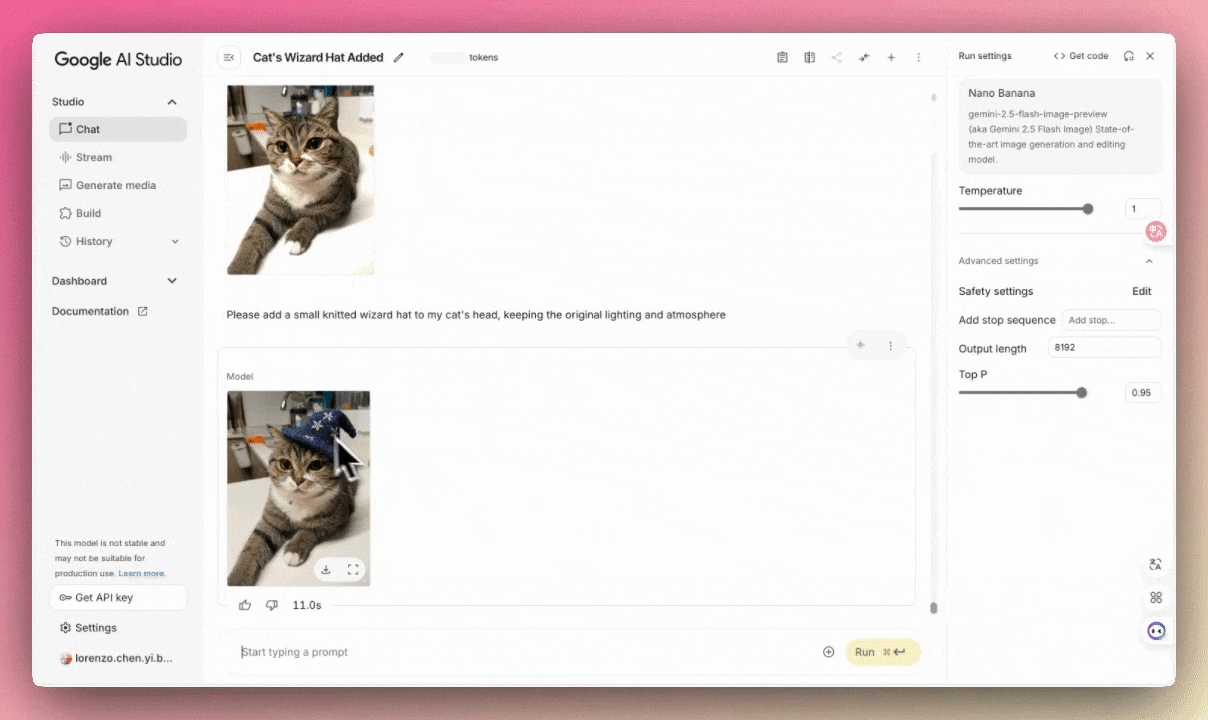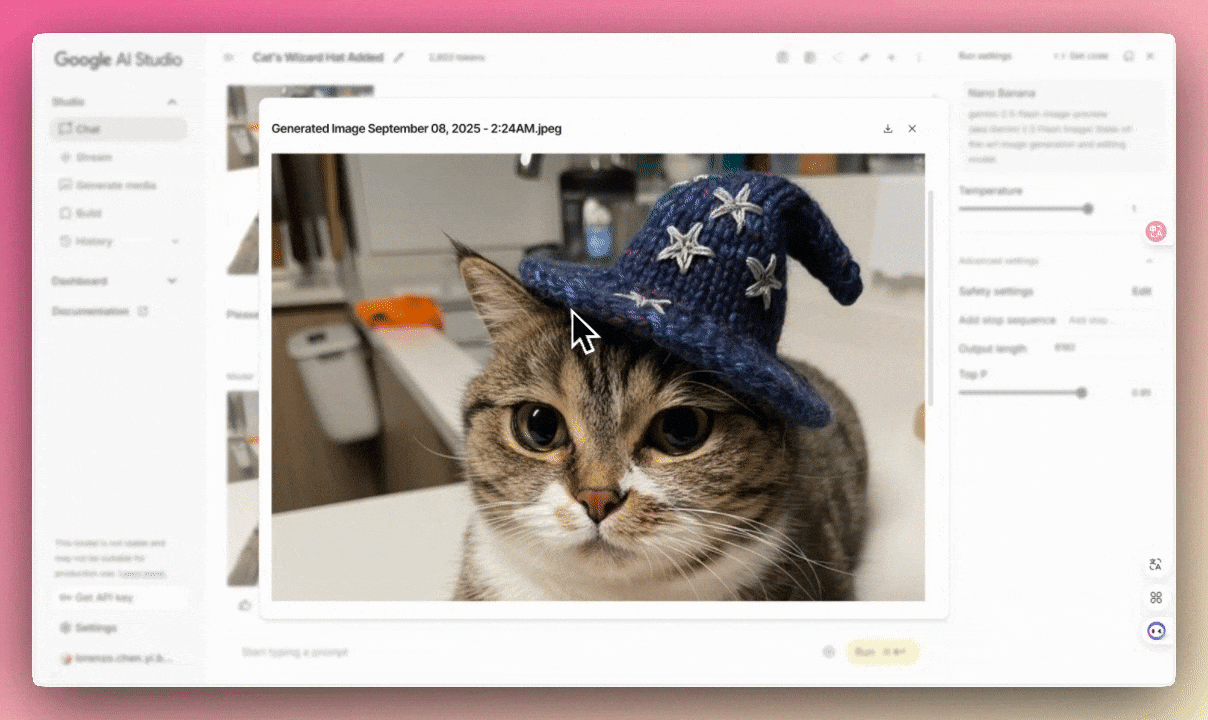
- 图像编辑&合成 Gemini 2.5 Flash Image 最厉害的功能之一,能在保持高度一致性的前提下,更改图中的物体:

例:请在我家猫的头上加一顶针织小法师帽,保持原有光线氛围。(出境:编辑家的??)
甚至能把两张图拼在一起:

例:让左侧模特穿上右侧图片图片里的蓝色波点连衣裙和蓝帽子
PS:今天的推送头图的角色也是 Nano Banana 生成。

指令如下——
Add several extra arms to this character, posing like the Buddhist "Thousand-Armed Avalokiteshvara" to convey many abilities in one person, with hands holding a keyboard, mouse, pencil, stylus, and digital camera. 8-bit style, white background. Facial expression with eyes closed, giving a very zen feeling; remove the two downward-facing hands and arms. Angle facing forward.
根据我们的测试以及社区的讨论, Gemini 有时候对中文的提示词响应不佳,偶尔会出现不生成图片的问题。
这时候我们不妨用沉浸式翻译的输入框增强功能,输入提示词后三击空格键,将指令转换为英文文本,就有可能大幅提升图片生成准确度哦。
想阅读原文档的朋友可以扫下面的二维码,获得通过沉浸式翻译
想阅读原文档的朋友可以扫下面的二维码,获得通过沉浸式翻译 BabelDOC 翻译的双语版本——

Step-Back Prompting
退一步,答案更清楚
我们常常希望 AI 能像一位聪明的学生,接到问题就立刻解答。但 DeepMind 最近提出的一种方法告诉我们:急着回答,反而容易错。
以往我们习惯对 AI 下命令:“请回答这个问题”“请总结这篇文章”。这种做法直截了当,但也容易把模型逼进死胡同:细节一旦处理错了,后面的推理就全偏了。
而 Step-Back Prompting 的思路是——先退一步,别急着解题,让模型先生成一个更抽象、更通用的“后退问题”,比如“这个现象背后的物理原理是什么?”“这位科学家的教育经历大体如何?”
再让模型回答这个高层次的问题,最后基于抽象出的原则和脉络,重新回到原题。
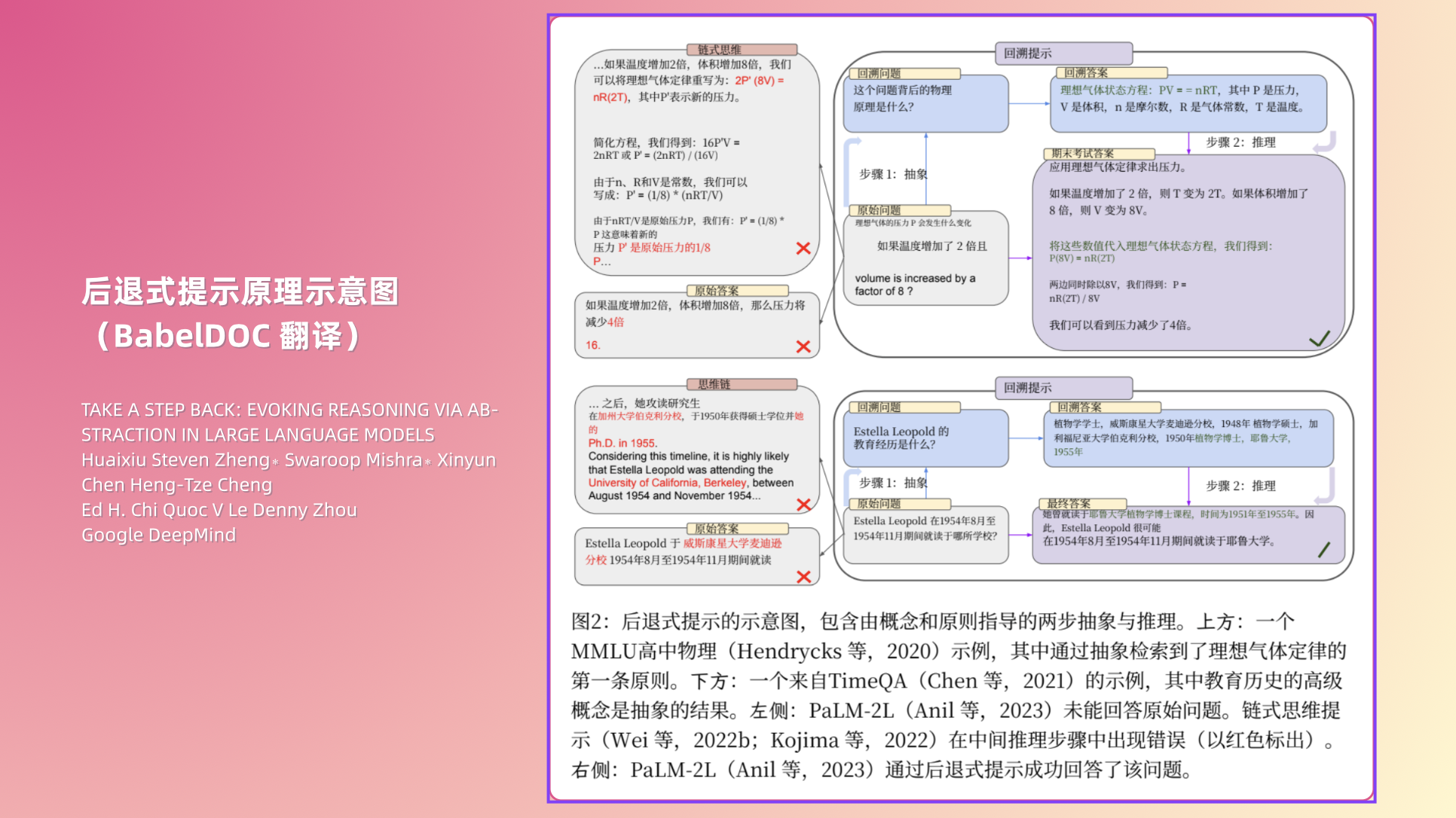
这种方法的妙处在于:抽象比推理更容易学。
模型可能在长链条推理上很容易犯错,但在“先抓住核心规律,再顺势往下解”时,错误率显著降低,让 AI 更贴近“人类专家思考方式”的方法论。
如果说以往的指令教学更像是“让 AI 去执行”,那 Step-Back Prompting 更像是“让 AI 去理解”。这种转变,可能会让我们重新思考如何和 AI 协作——
陪它退一步,看得更远。
论文发现,有三种场景特别适合这种指令方式——
- **学习/科研:**让 AI 先总结“涉及哪些定律/概念”,再解题;
- **信息检索:**不要直接问“某年某人在做什么”,而是问“这个人的整体履历是什么”;
- **日常写作:**处理复杂主题时,可以先让 AI 抽象出框架,再逐层回填细节。
可以尝试下面这一系列指令,用“退一步”的方法获得更精确的答案——
指令前半截,请三选一:
// 以下指令用来检索信息
你是一位信息整理专家。
在回答具体问题前,请先提出一个更抽象的后退问题(Step-Back Question),它应当能涵盖更广泛的脉络(例如人物履历、历史时间线、主题框架)。
请先回答后退问题,再回到原问题,给出最终答案。
## // 以下指令用来检索信息
// 以下指令用来检索信息
你是一位科研助理。
在回答问题前,请先生成一个更高层次的后退问题(Step-Back Question),它应当涉及该问题背后的科学原理、通用定律或研究脉络。
请先回答后退问题,再基于这些原理逐步推理原始问题。
// 以下指令用于写作
你是一位擅长抽象和发散思维的写作者。
在创作或回答问题前,请先提出一个更抽象的后退问题(Step-Back Question),它应当帮助提炼主题的核心概念、价值取向或更普适的叙事框架。
请先回答后退问题,再基于这些抽象出的主题展开逐步推理,最后完成写作或给出创意答案。
指令后半截,可粘贴在上面的指令之后,用于要求 AI 根据格式输出结果——
原问题: {用户问题}
输出格式:
Step-Back Question: ...
Step-Back Answer: ...
Reasoning Steps: ...
Final Answer: ...
感兴趣的朋友可以扫下面的二维码,获得沉浸式翻译 BabelDOC 翻译版 Deepmind 论文双语版本——

密度链提示
让摘要像资深编辑一样提炼关键信息
我们习惯对 AI 说:“总结一下”。结果往往是一个四平八稳的段落,信息不够全,或者细节被删得太狠。
哥伦比亚大学和麻省理工的研究者提出了一个新方法,叫 Chain of Density(密度链提示,CoD),它让 AI 摘要的过程更像一位资深编辑的“逐步打磨”。
论文提出的思路很巧妙:先让模型写一个稀疏摘要,信息点少、用词松散;
然后迭代 5 次,每次都要求它在不增加长度的前提下,加入 1–3 个新的关键信息点(原文称之为信息实体,missing entity)。
为了腾出空间,模型必须学会**压缩、融合、改写。**就像在“稀汤寡水”里加入更多来自原文的“食材”,但又得保持汤的总量不增加。
最终的摘要往往比直接生成的更紧凑、更有信息量,甚至和人工写的信息密度相当。我们尝试让 ChatGPT 根据论文的理论,生成了一套指令——
你是一位资深编辑,负责对文章进行逐步浓缩的摘要工作。
请使用“密度链提示(Chain of Density, CoD)”的方法生成摘要。
步骤要求:
1. 先写一个信息稀疏的初始摘要(80词左右),尽量模糊笼统。
2. 然后迭代 5 次:
- 每次识别出 1–3 个在上一个摘要中缺失的关键信息实体(Missing Entities)。
- 将这些新实体加入摘要,但保持摘要总长度不变。
- 为了腾出空间,请对已有内容进行压缩、融合、改写,而不是删除已有实体。
3. 每次迭代的输出都要包含:
- Missing Entities: [...]
- Denser Summary: ...
输出格式:
请用 JSON 列表输出,包含 5 个对象,对应 5 次迭代。
每个对象的键为
"Missing_Entities" 和 "Denser_Summary"。
输入文章:{{在这里粘贴文章正文}}
我们用这个指令,对 SemiAnalysis 关于 OpenAI 可能打造 ChatGPT 超级应用进行广告变现的文章进行了总结。
链接在此:https://semianalysis.com/
链接在此:https://semianalysis.com/2025/08/13/gpt-5-ad-monetization-and-the-superapp/
第一次迭代的总结(翻译): GPT-5 让许多 Pro 和 Plus 用户感到失望,但 OpenAI 的设计重点其实是其超过 7 亿的免费用户。只关注模型能力的分析人士忽略了一个事实:ChatGPT 已经跻身全球前五大网站。此次发布的核心是一个路由系统,它在性能与成本之间取得平衡,让免费用户能够接触到更深度的推理模型,并为 OpenAI 将这一庞大且快速增长的未变现用户群体货币化做好准备。
第五次迭代的总结(翻译): GPT-5 的路由器让 OpenAI 能够通过分类查询并在规模化下启用推理,从而将其超过 7 亿的免费用户货币化。Altman 语气的软化与 Fidji Simo 的专业背景,指向了通过抽成而非广告的代理式消费路径。高价值查询可能带来推荐收入,例如 ChatGPT 代用户预订机票或采购杂货。借助 Stripe、Shopify、Instacart 和 Booking.com 等合作伙伴,OpenAI 正致力于打造一个可与 Google、Meta 和 Amazon 竞争的消费者超级应用。
第五次的迭代不但包含了关键数字,人物的立场变化,主要的手段,以及达到的目标,还明显将一些不是很重要的信息进行了过滤,增加了更关键的信息点。
以后碰到更复杂的文献,就能更好地生成摘要了。

想阅读原论文的朋友可以扫下面的二维码,获得通过沉浸式翻译 BabelDOC 翻译的双语版本——

思维模型工具箱
给大脑加一套思维外挂
有时候,我们遇到问题时会有种熟悉的无力感:
脑子里观察、思考和解决问题的方法,就那么几种自己最习惯的,容易陷入旧经验的窠臼,缺少能真正打开局面的东西。
效率社区 Ness Labs 整理了一份 思维模型工具箱,收录了 100 多种跨学科的模型,按决策、问题解决、学习等场景分类。
举几个例子:
- 帕累托法则(80/20 法则):提醒你别均匀发力,先找到那 20% 的关键因素,往往能解决 80% 的问题。
- 汉隆剃刀:在遇到冲突或误解时,先假设原因是疏忽或无知,而不是恶意。这能让判断更冷静,也避免过度解读。
- 艾森豪威尔矩阵:一种决策模型,帮你根据任务的紧迫性和重要性对其进行优先排序,从而提高效率。
在工具箱里,你还能看到“第一性原理”“二阶思维”“博弈论”这些常被提到的思维方式,每个模型都配有简洁的解释与场景应用,读完就能上手。
搭配沉浸式翻译使用,你可以无障碍地在中文语境下理解这些来自全球的认知框架。
你甚至可以直接把“100 种模型的清单”丢给 AI
你甚至可以直接把“100 种模型的清单”丢给 AI,让它帮你挑选最适合解决眼下问题的三种思维方式。这样一来,AI 不再只是“回答问题”,而是真正和你并肩思考。
而这只是这个工具的诸多玩法的一种。
链接:https://toolbox.nesslabs.com/tools
One More Thing
105 页的提示词“魔法书”
在看完前面这些内容之后,还有一个值得特别提出的收尾。 那就是 OpenArt 社区整理的《Prompt Book》——一份长达 105 页的提示词写作手册。
不要看这本手册有点老(2022 年发布),甚至早于GenAI 进入公众视线前。
它的重要性在于把“如何和文生图大模型对话”拆解得足够清晰:
- 提示词应该有结构(主体 → 细节 → 风格 → 摄影语言 → 质量增强)。
- 修饰词和“魔法词”的用法,比如 HDR, 8k, cinematic lighting, highly detailed,能让画面瞬间质感翻倍。
- 负面提示的技巧(如 blurry, deformed, extra limbs),能显著减少 AI 常见的“翻车”场景。
- 还有种子(Seed)、CFG、Steps 的参数调节方法,让出片不再完全靠运气。

换句话说,用更精准的指令,控制图片生成的过程。
虽然它是为 Stable Diffusion 这样的开源模型准备的,一些概念也稍显老旧,但像 Nano Banana 这类新一代更高效的模型,其实同样吃“语言输入”的细腻程度,同样可以受益于这些技巧。
所以,你可以把这本手册当成 提示词的通用语法:
- 在旧模型上,它帮你突破“出片随机”的困境;
- 在新模型上,它帮你释放“模型强大理解和生成力”的优势。
在信息过载和模型迭代的双重浪潮里,这再次提醒我们一个关键但经常被忽略的问题
AI 再强大,也需要人类写好问题。否则,就是 Garbage in, garbage out(垃圾进,垃圾出)。
可以扫描下方二维码,获取沉浸式翻译 BabelDOC 翻译过的双语版提示词写作手册——

以上这五个内容,都是一些能随时放进日常工作和学习里的小工具和技巧。
如果你也常常在收藏夹里堆满资料,却迟迟没能消化,不妨挑一两个试试,搭配上面的技巧,加上沉浸式翻译,说不定就能立刻用起来,打造你自己顺手的工作流,或者把一直想尝试的 AI 图片生成给跑一跑,看看用上这些技巧后,抽卡有没有惊喜。
如果你有私藏的**「沉浸式翻译 + ??」的使用故事和创意玩法**——不论是阅读、学习、工作、娱乐还是协作场景,欢迎投稿!


