
在使用沉浸式翻译,调用 AI 翻译服务时,一些用户会发现一个现象。
即便只是翻译短短的一句话,例如经典的 “Hello world”,系统记录的 Token 消耗量也可能远高于这几个单词的实际长度。
这让不少人困惑——为什么输入文本很短,Token 却用得这么快?
这背后,涉及到大语言模型翻译与传统机器翻译在计费和运作方式上的根本区别。
AI 大模型处理信息时,要先把文字转成一种叫 Token (有翻译为「令牌」也有翻译为「代币」,本文统称为 Token)的最小单位。无论是用户输入的内容,还是系统给它的指令,都要先变成 Token 才能被模型理解和运算。
因为模型需要对每一个 Token 进行计算,所以只要它接收了信息,就会产生 Token 消耗,哪怕这些信息只是背景说明或格式规则。
而常见的大模型在计费规则上,都会对输入和输出的 Token 进行区别化定价。
例如,GPT-5 模型的 Token 输入价格是 1.25 美元/百万 Token,GPT-5 mini 输入价格则是 0.25 美元/百万 Token。
输出价格上,GPT 来到了 10 美元 / 百万 Token,GPT-5 mini 则是 2 美元 / 百万 Token。
我们用 OpenAI 官方的 Token 计算器看一下,翻译 「Hello World. 」的输入token计算情况——
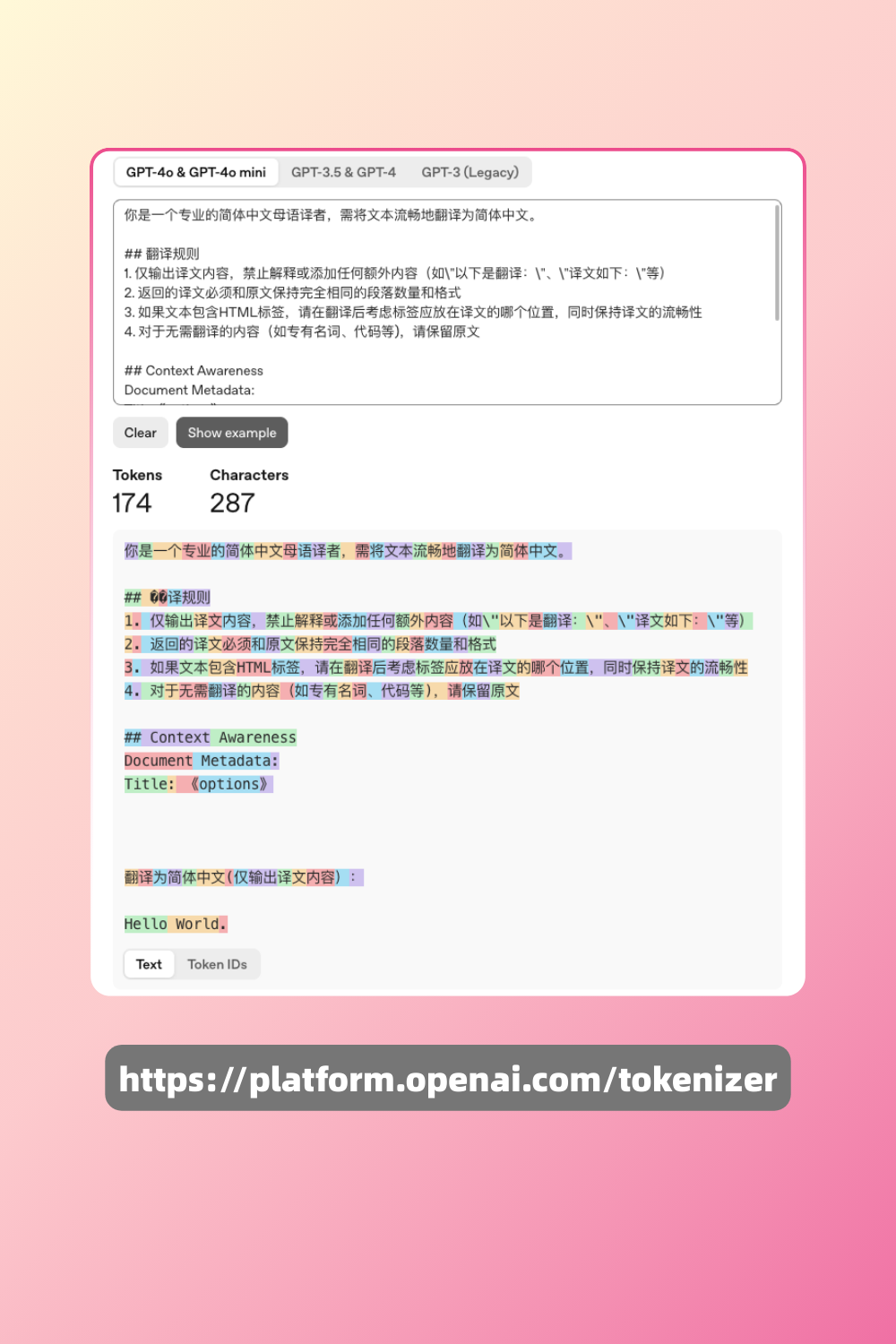
(注:OpenAI 官方计算器暂未提供 GPT-5 模型的 Token 计算器。)可以看到,纯文本内容输入后,AI 大模型计算为 174 个 Token。由于使用的词表不同,同样的文本在不同的大模型下消耗的 Token 数量也会不一样。这里我们用 Token 计算器算了一下用同样的指令翻译 「Hello World.」,沉浸式翻译接入的 AI 大模型需要消耗的 Token 数:
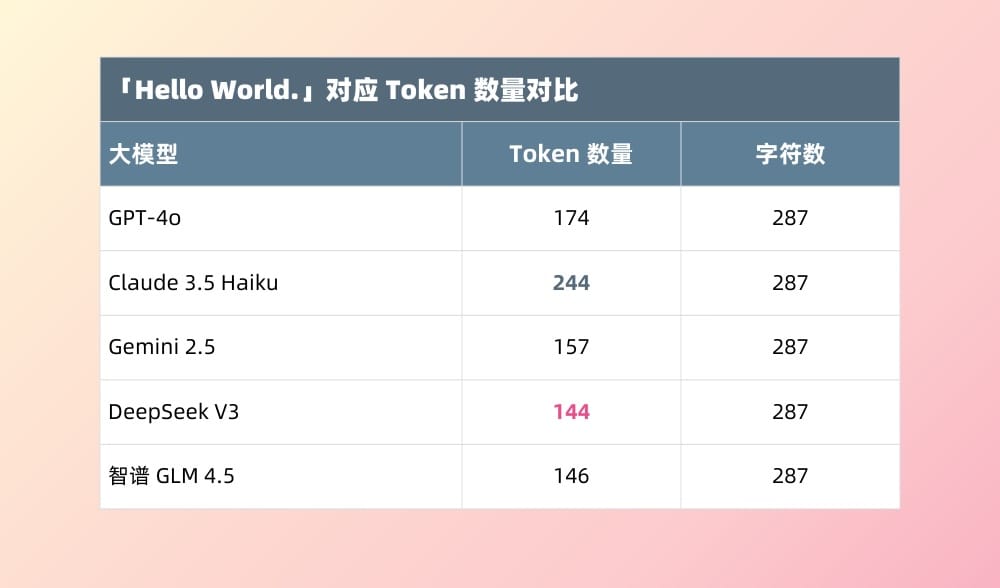
此外,OpenAI还需要添加一些必要的特殊标记,最终该请求的输入Token 是181个。下图是文本输入后 GPT 模型完成翻译并返回的 Token 计算情况:
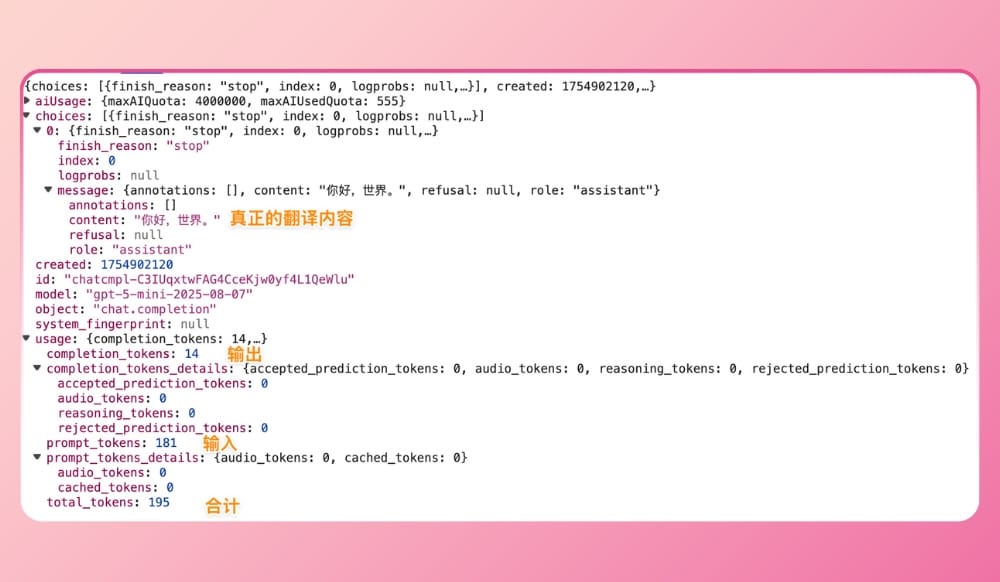
截图可见:提示词输入 181 个 Token,输出 14 个 Token,合计使用 195 个 Token。OpenAI 等 AI 模型在处理翻译任务时,会额外包含指令相关的 Token 消耗,因此扣费的 Token 数通常会高于文本本身的长度。
当翻译文本较短时,这部分固定的指令 Token 开销占比会更高。这是大模型特性决定的固定成本。
为此,沉浸式翻译引入了「多段翻译」技术,将一次指令应用于多段文本,从而摊薄这部分开销。
下方是我们使用的多段翻译提示词,提示词本身需要约 240 个 Token ,但是一次指令输入可翻译 4 段话,这样就能摊薄这个开销——
你是一个专业的简体中文母语译者,需将文本流畅地翻译为简体中文。
## 翻译规则
1. 仅输出译文内容,禁止解释或添加任何额外内容(如\"以下是翻译:\"、\"译文如下:\"等)
2. 返回的译文必须和原文保持完全相同的段落数量和格式
3. 如果文本包含HTML标签,请在翻译后考虑标签应放在译文的哪个位置,同时保持译文的流畅性
4. 对于无需翻译的内容(如专有名词、代码等),请保留原文
## Context Awareness
Document Metadata:
Title: 《React》
## 输入输出格式示例
### 输入示例:
Paragraph A
%%
Paragraph B
%%
Paragraph C
%%
Paragraph D
### 输出示例:
Translation A
%%
<div class="cta-placeholder" data-cta-style="banner"></div>
Translation B
%%
Translation C
%%
Translation D
翻译为简体中文:
React
%%
The library for web and native user interfaces
%%
Learn React
%%
API Reference
希望这篇文章能解答你关于 AI 翻译额外 Token 开销的疑惑。


