
BabelDOC 一直想把 PDF 翻译这件事做得更好一点。
我们的目标很明确:在合理的成本下,提供稳定、可靠的高质量翻译。要能保留复杂的排版、公式、图表、矢量图,甚至多页跨表格的格式结构,同时翻译质量不打折。

在最新版本的 BabelDOC 中,我们对翻译流程的底层逻辑做了个调整——
此前我们跟大家汇报过,BabelDOC 增加了术语提取功能。
让模型在正式翻译前,先读懂文档、提取出关键术语表,然后,大模型会先翻译术语,再套用到全文中。
在技术文档、科研论文、产品白皮书这类文本里,最容易出问题的不是句法,而是术语。
同一个词在上下文不同段落被译成不同版本
同一个词在上下文不同段落被译成不同版本,会让全文显得“不专业”。
同时,虽然术语库这个功能虽然早已上线,但手动生成、添加,以及维护一个术语库,对于不少朋友来说还是有点繁琐。
所以我们决定让模型自己生成术语表,用上下文语义来确定关键术语,这样既智能,也能自动适应不同类型的文档。
听上去不错,但实际测试时发现:不同模型做“阅读理解”的能力是不一样的。
我们测了几个主流的大模型,目前大家爱用的 DeepSeek 和 Qwen 提取术语的能力都不太够看。其中 Qwen 可能改进空间还更大点儿……

虽然大部分关键词都能识别到,但这俩模型在总结时会混进一些不太相关的内容,比如普通名词或者一些本不该被列为术语的字符。
这些“噪音”在术语表里出现得越多,后续翻译质量就越差
这些“噪音”在术语表里出现得越多,后续翻译质量就越差。
在多轮对比测试后,我们注意到一个表现比较突出的模型, KIMI。
尽管近期在大模型“卷”的浪潮中稍显“过气网红”,但 KIMI 在阅读全文方面能力相当不错。
我们尝试了几十份不同类型的 PDF,KIMI 的术语提取结果都显著优于其他模型。换句话说,KIMI 在上下文语义判断和关键词筛选上的能力更强。 简单来说,它更容易“看懂”文档里什么是概念、什么是修饰。
不过,这个世界上也没有完美的解决方案——
如果让 KIMI 同时负责术语提取和全文翻译,效果确实不错,但成本高得有点夸张。
按我们内部的测算:以 DeepSeek 的成本为 1,Qwen 大约是 0.3,而 KIMI 是 2。
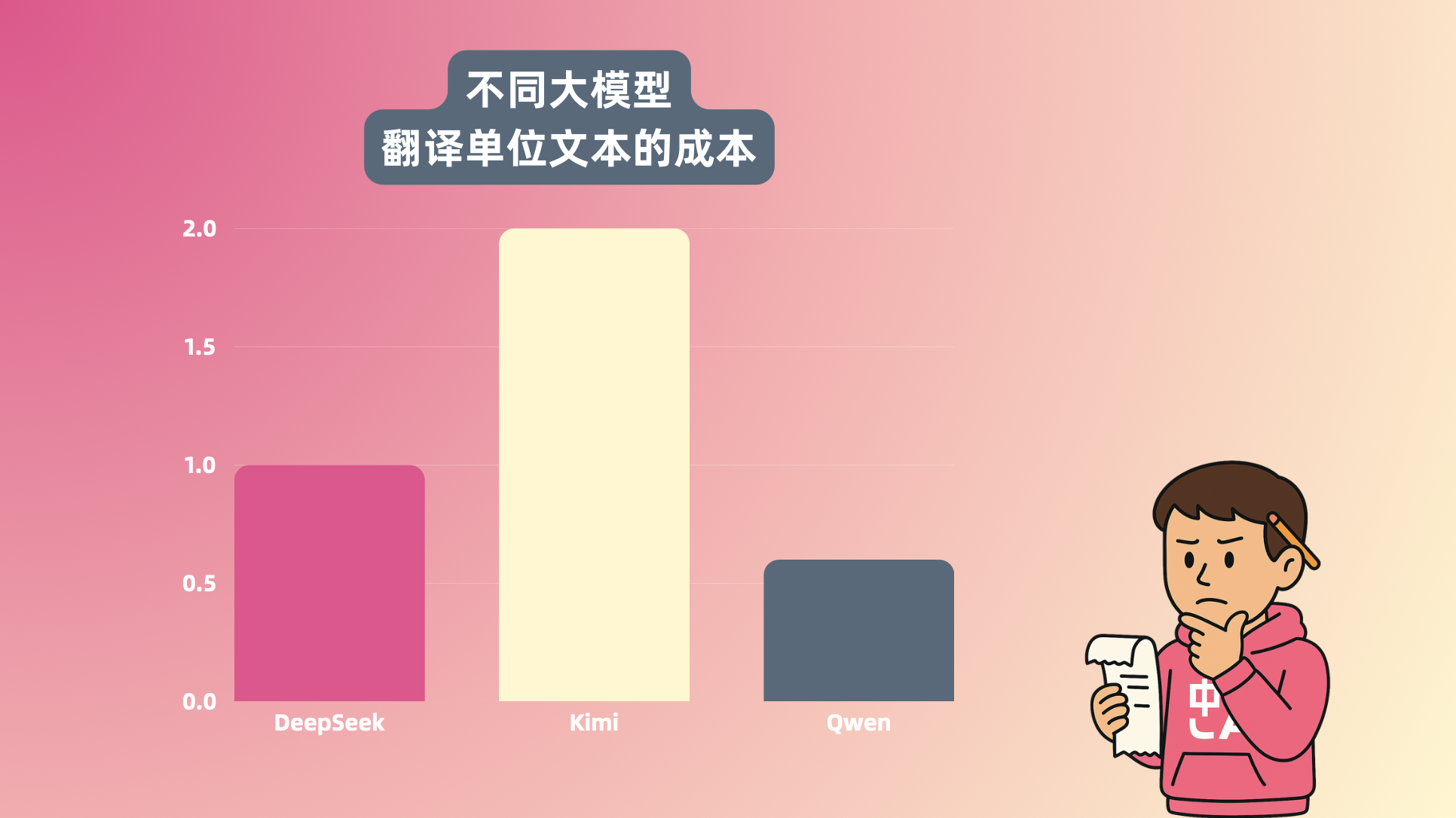
这意味着同样一份论文,KIMI
这意味着同样一份论文,KIMI 翻译一遍要花掉其他模型两倍的成本。
所以我们换了个思路:要不让不同的模型分工合作一下,各自做擅长的事情?
具体方案是这样的:
- KIMI 负责术语提取。 它的强项是阅读理解和信息筛选,能保证术语表质量;
- DeepSeek 或 Qwen 负责全文翻译。 这两款模型在翻译执行上速度快、成本低、稳定性好;

在内部测试中发现,使用 KIMI 最新模型 K2 进行术语提取,相较于全部使用 DeepSeek 或 Qwen,不仅提取出的术语总量得到了更优的控制,在相同文件上还能进一步节省少量 Token 开销。
这不喜大普奔了?
在最新版本中,你可以根据自己的偏好,直接选择不同组合——
在最新版本中,你可以根据自己的偏好,直接选择不同组合——
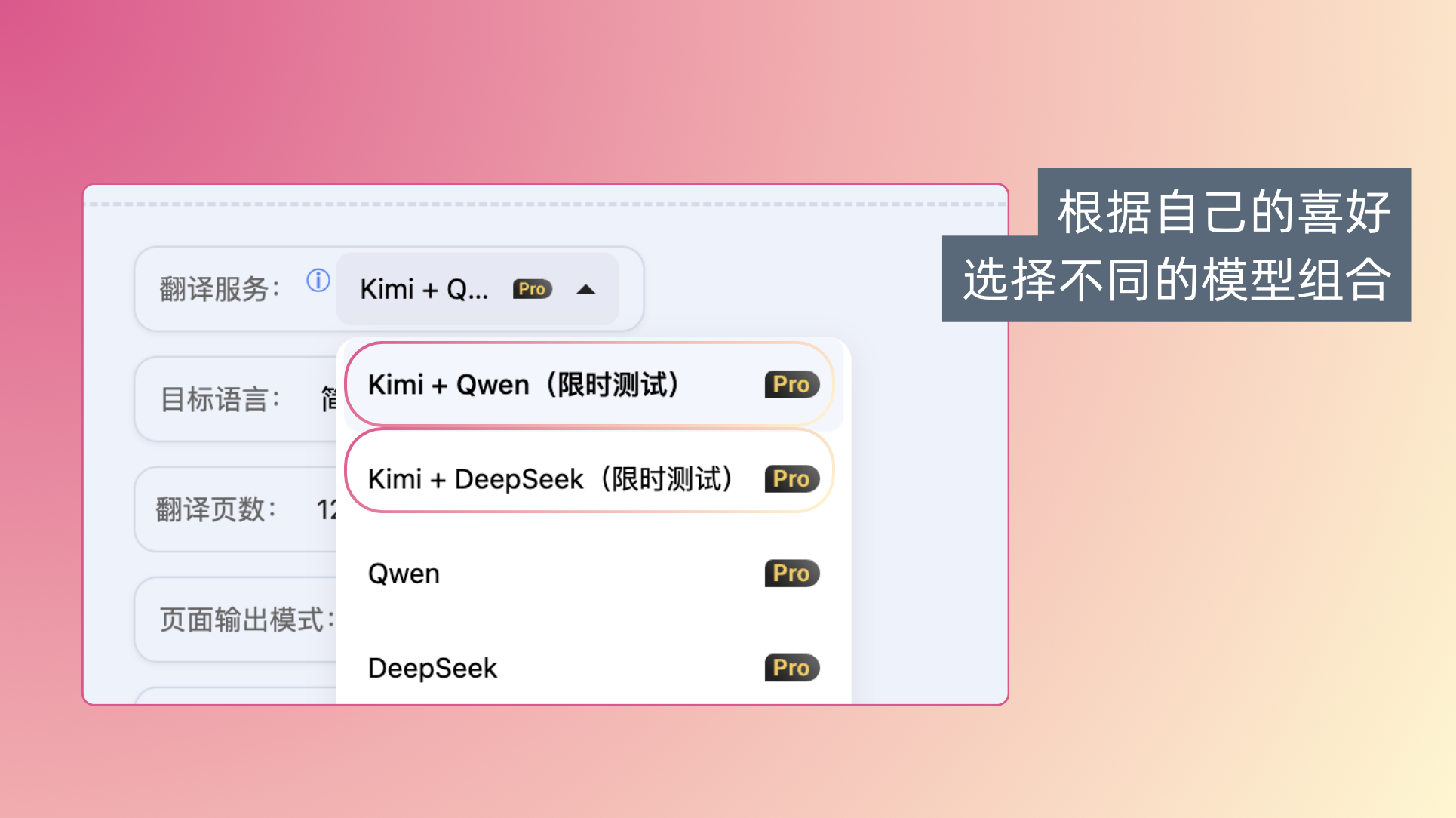
然后记得打开「自动提取术语」功能,方可生效。

其实,从研发视角看,这次改动算是一次翻译架构不大不小的升级。
它体现了我们在做 BabelDOC 时一直坚持的方向:“不求最贵,只求最好”不是我们的目标,**而是不断找出最合适的技能搭配,**让 AI 的计算力真正用在提高质量的地方,每个 Token 都花得更值一点。
哪怕只是让计算中心的能源消耗少那么一点点点点……呢
哪怕只是让计算中心的能源消耗少那么一点点点点……呢?
最后,真诚地感谢每一位 BabelDOC 用户。
你们的使用、反馈和建议,帮我们不断发现问题、完善功能。团队目前人手仍然有限,我们还是无法回复每一条反馈,但请相信,每一条反馈我们有认真看。
很多优化思路,其实就是从用户的具体问题里生长出来的。
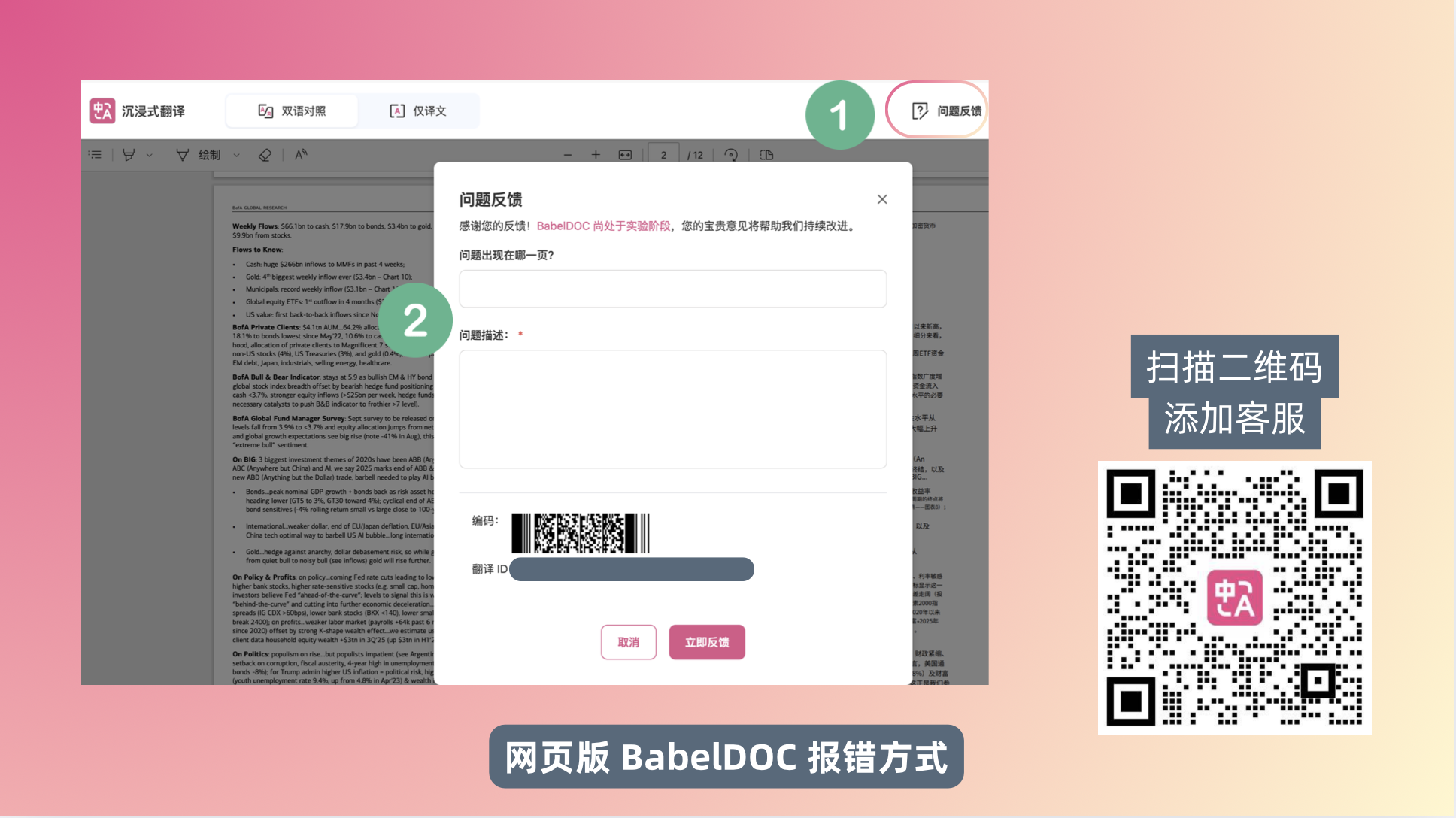
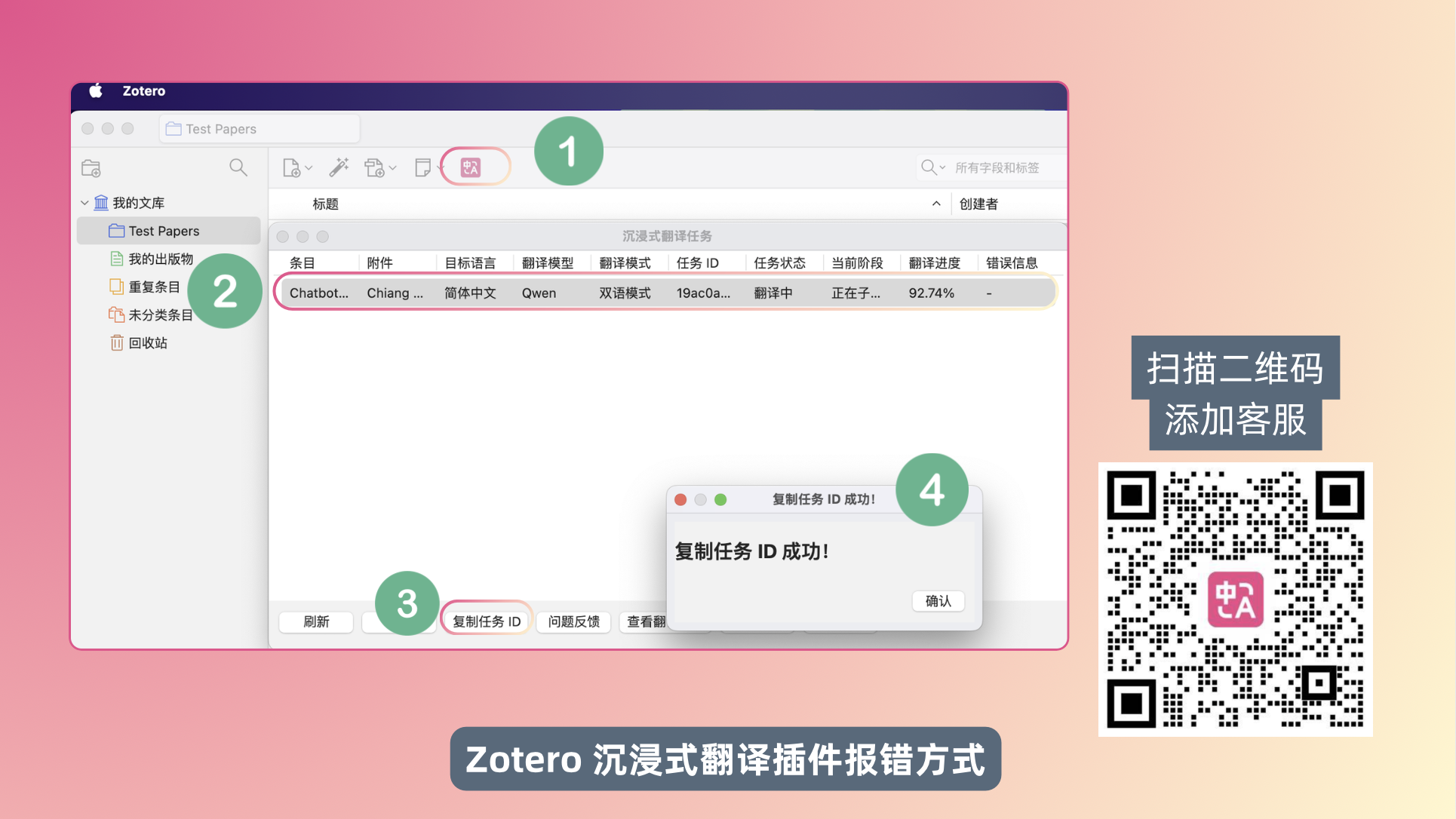
如果您遇到文档翻译问题,请保留翻译 ID 并联系客服,我们会帮您排查。
如果你在使用过程中遇到翻译质量严重异常,我们会进行审核并退还相应额度。这种情况下请务必添加人工客服。
网页版 BabelDOC 报错方式——
Zotero 插件版报错方式——
我们在努力让 BabelDOC 成为一个真正值得信任的工具,希望一路上继续得到大家的信任和支持!PS:今天的头图——



