
今天的主角是安静了很久的 BabelDOC。
给新来的朋友介绍一下,BabelDOC 是沉浸式翻译旗下一款专注 PDF 场景的 AI 翻译工具,主打以下特点:
- 无损解析:完整提取PDF内嵌图表、脚注、公式等非文本元素
- 精准还原:译文与源文件保持像素级版式对齐
- 智能优化:自动识别学术论文/招股书/行业白皮书等专业文档结构,确保翻译后布局与数据可视化效果,同原文档高度一致
目前市面上有不下数百款 PDF 翻译工具,各有各的特点。而 BabelDOC 的优势在于从 PDF 文件架构出发,在解析、翻译、重构等方面进行了大量创新和优化,达到了与同类产品相比更为优质的重排效果。
对 PDF 的前世今生,以及 BabelDOC 的工作原理感兴趣的朋友,不妨回顾一下这篇文章上新|BabelDOC PDF:极致文档翻译体验是这样打造的。
而正因为在 PDF 翻译工作和产品工程上的诸多创新,自从 BabelDOC 在 GitHub 上开源以来便成了热门项目,最高达曾达到全站第三名。(可以回顾这篇了解一下当时的盛况:BabelDOC 登上 Github 热门榜前三:技术极客们的春日狂想。
BabelDOC 的项目负责人 AW 是个不折不扣的技术狂人,还没毕业就已经是小有名气的 GitHub 大佬。自从今年 4 月 BabelDOC 更新了对韩语的支持后,AW 大佬每天忙于钻研各种用户提交的奇形怪状的 PDF,并不断优化产品,沉寂了将近半年后,终于捧出了又一个史诗级别更新——
BabelDOC 0.5
我们迫不及待地找 AW 聊了聊,看看这半年都有什么新进展。
据大佬自述,这半年以来,几乎一周一小版本,一个月一个大版本。历次更新都围绕一个核心目标——让翻译更自然、更顺畅。
BabelDOC 0.5 的进步,我们一一为你解析——
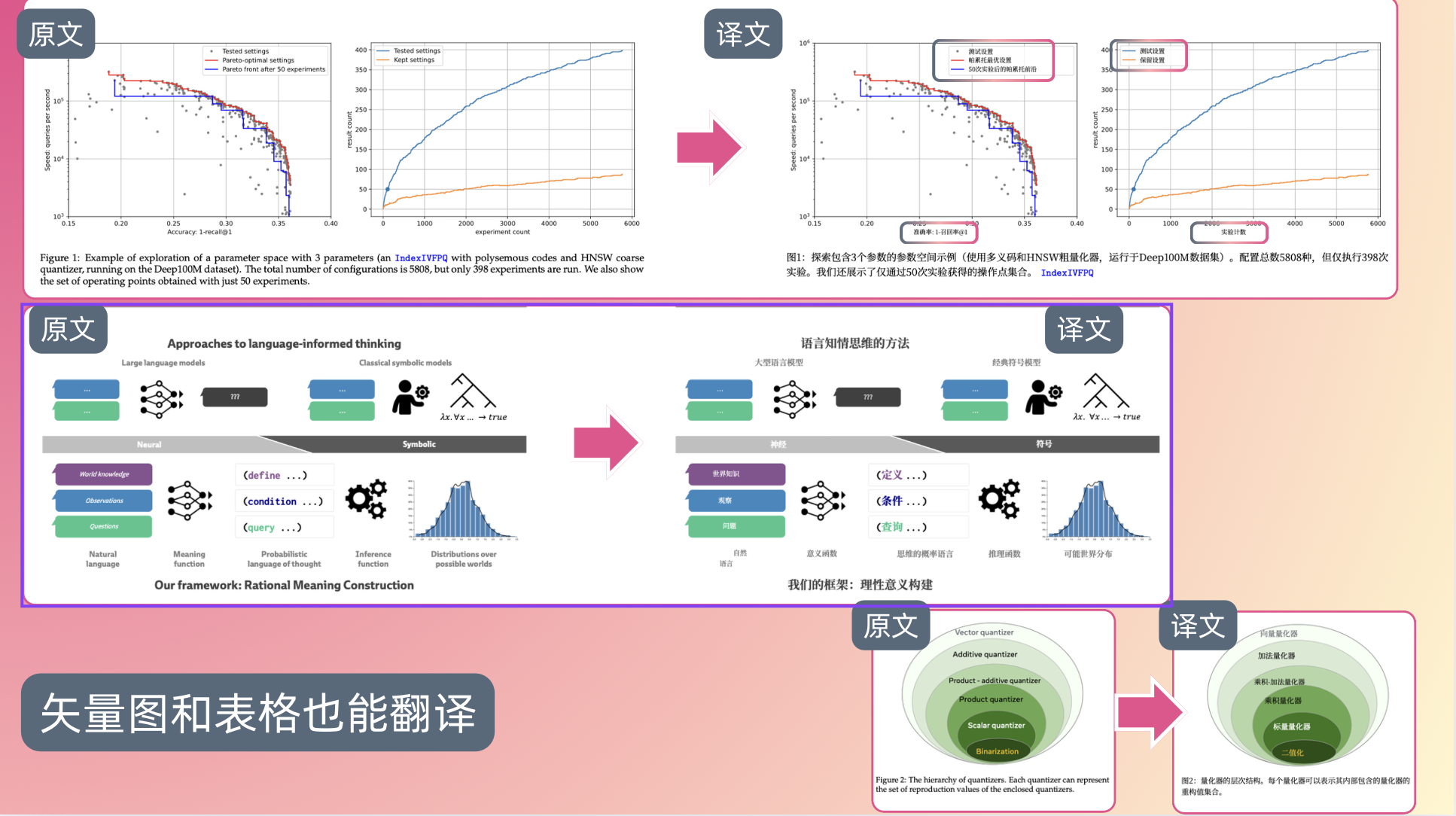
重磅!矢量图和表格也能翻译了!
很多用户都经常问, 什么时候 BabelDOC可以翻译图表里的文字。
这一天终于来了!
经过几个月攻关,新版本已经可以翻译表格和矢量图中的水平文字了!
在此之前,旧版 BabelDOC 会直接跳过图表和矢量图的文字内容。
大家可以点开下面的大图感受一下——
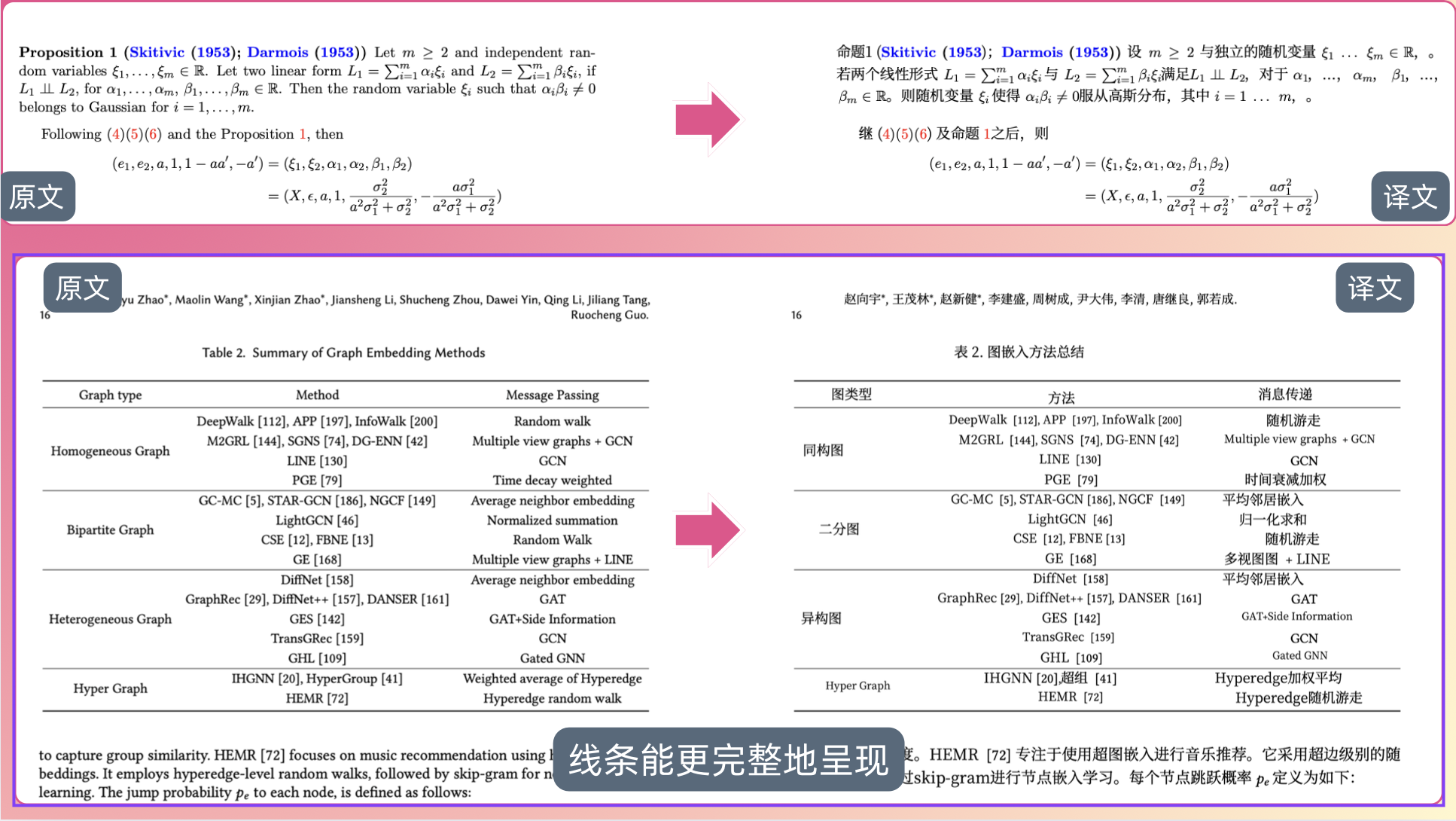
公式和表格线条优化
细细的线条是 BabelDOC 的大大大问题。
在此之前,BabelDOC 会把公式里的分数线、根号横线,以及表格的一些线条弄丢。这给表格、公式的阅读造成了困扰。
现在,经过多次迭代优化,表格和公式里的线条终于得以保留,译文的排版也更接近原始文件了——
跨页段落连贯性增强
使用旧版 BabelDOC 翻译 PDF 时,如果一句话正好跨栏或跨页,就会被拆开翻译,导致译文断裂、不连贯。
现在,系统对这类问题进行了优化,能自动识别并合并这些跨页段落,翻译出来顺畅得多。

例如图中这份论文的 第二页到第三页的交界处,有一句原文**(...and filtered search [Gollapudi et al., 2023].)**被拆分成了两个部分。
如果是旧版 BabelDOC,会把 filtered 和 search 分为两个断句进行翻译**(“……及过滤功能。”和“搜索 [Gollapudi 等人, 2023]。”)**。
而新版 BabelDOC 能够识别这个被切断的句子,让他们重组,从而正确输出译文,并遵循原始排版将译文分布在两个页面的第一行和最后一行**(“……及过滤搜索 [Gollapudi等人, 2023]。”)。**
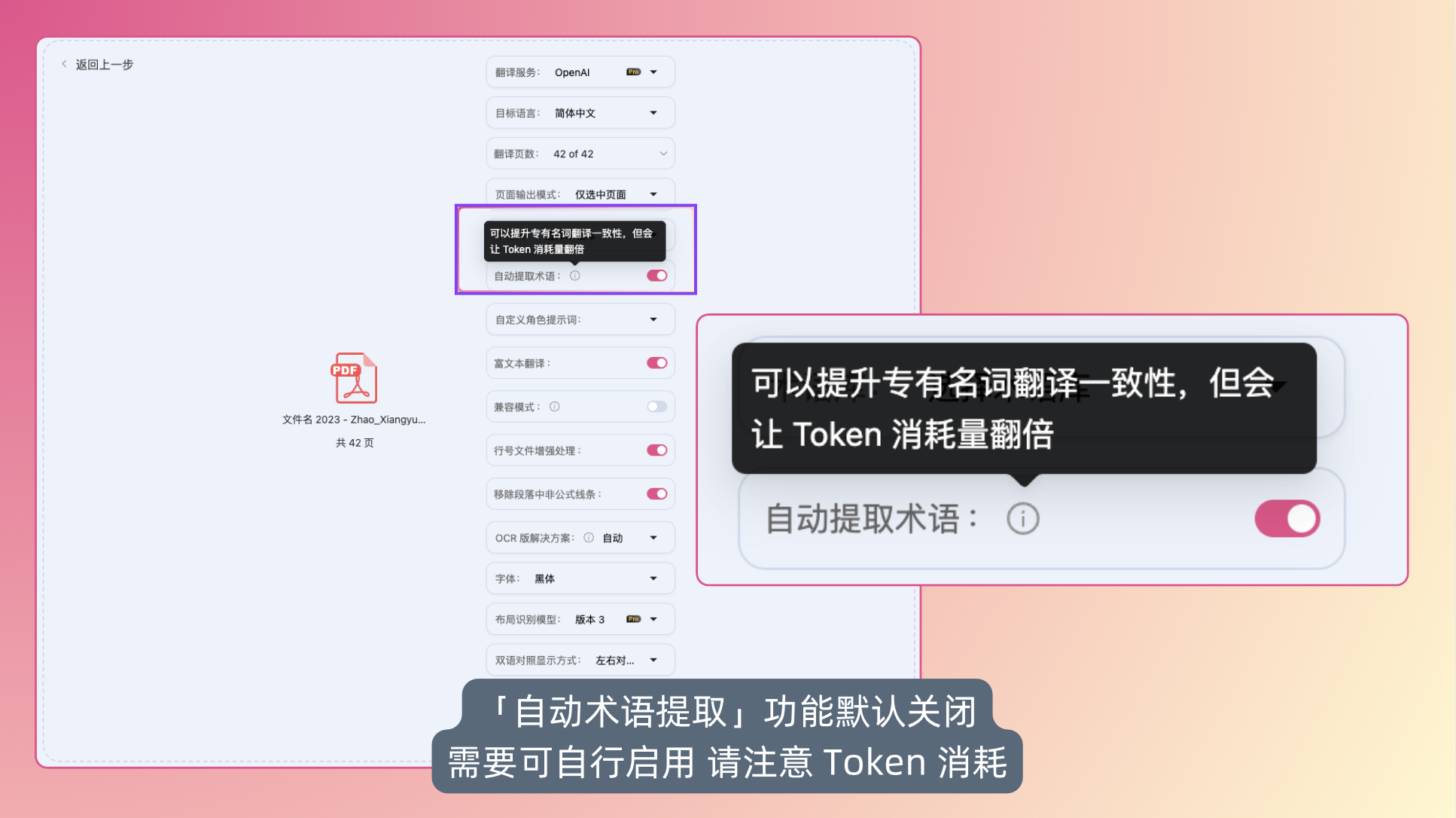
术语更加统一
此前很多用户反馈,同一个术语在不同的段落中,可能会被翻译成不同的词语。
原因是在旧版本 BabelDOC 中采用的是并行翻译技术,能够加快翻译速度,但缺少统一术语机制。
现在,新版本加入了术语提取功能,在翻译时会进行以下步骤:
- 先扫描全文,识别出重要术语;
- 给每个术语协商一个唯一的译法;
- 在翻译过程中自动应用,保证全篇术语一致。
从而尽可能保证术语名词在同一篇 PDF 文档中译文的一致性。

??注意:正如我们此前解释的一样(答疑|为什么用大模型翻译时,Token 消耗会多于文本长度),打开术语提取功能后,由于指令、文本额外处理、术语提取返回等流程,会消耗更多的 Token,这一功能默认是关闭的。
有需要的用户朋友可以在翻译时自行选择打开这个功能——
字号大小更稳定
原文和译文的长度经常会不同。通常来说,从英文翻译为德文可能会产生 20%-30% 的篇幅膨胀,而英文翻译为中文日文等东亚语种则会反过来,出现篇幅缩小。
旧版 BabelDOC 的动态缩放是逐段计算。
这就导致了有的段落字很大,有的又很小,看起来不美观。
现在,BabelDOC 0.5 版引入了「二阶段排版」技术:
- 先为全文计算一个统一的缩放比例;
- 大部分段落用统一比例显示;
- 只有极少数重排过程中实在放不下的段落,才会继续缩小。
这样一来,整份译文看起来就更加整齐,可读性和美观度都有明显的提升,如下图——

额度计算方式调整BabelDOC

自上线以来,经过多次优化,翻译效果日渐提升,使用量也大幅增长。
原有的「解析页数额度+翻译 Token 额度」计算模式已不能很好地反映当下现实。
因此,经过慎重考虑,我们将从 2025 年 10月 31日下午三点起,对额度体系进行调整。
- 取消 BabelDOC 页面解析额度限制,仅保留翻译 Token 额度限制。
- 所有 BabelDOC 用户每月可获得 50 万 Token 额度,用来在 BabelDOC 中使用免费翻译模型。
对于已经是 Pro 用户的朋友:
- 每月可享受高达 2000 万 Token的高级翻译模型额度(与沉浸式翻译额度共用)
对于已经是 Max 用户的朋友:
- 每月可享受高达 5000 万 Token 的高级翻译模型额度(与沉浸式翻译额度共用)
(Max 用户的顶级模型暂时无法用于 BabelDOC)
注意:免费模型实际可用性取决于上游供应商的供应情况,额度根据实际负载动态调整。
对于之前购买过 BabelDOC 页数加量包的朋友,无论是否使用,您的加量包会在额度调整生效后,进行如下转换:
每 10000 页解析额度 → 转换为 1000 万高级翻译模型额度
注意:如果您不希望进行额度转换,也可以联系人工客服,申请转换为其他类型的额度包或退款。
尾声
PDF 翻译是一个非常复杂的系统工程。一个个难题被攻克,又会有一个个新问题冒头。
翻译和排版状况依然会不断出现。这也催促着我们不能放慢脚步,要继续优化产品,加强和用户的沟通交流。接下来,我们还会在以下几个方面继续努力:
- 持续提升翻译质量;
- 支持更多文件类型;
- 优化使用体验。
最后,感谢所有用户的支持与反馈!你们的意见让 BabelDOC 不断变得更好。虽然团队人手有限,没能回复每一条反馈,但我们一直在认真倾听,每一条用户群中的消息我们都会看并及时跟进、尽力改进。
希望 BabelDOC 能继续做你学术研究、学习、工作之路上的翻译伙伴。
本文所展示的示例文档,选取自以下五篇论文的部分页面,相关内容依据 CC-BY 授权,使用 BabelDOC 进行翻译:
- Douze M, Guzhva A, Deng C, et al. The faiss library. arXiv preprint arXiv:2401.08281, 2024.
- Liu Y, Lin C, Zeng Z, et al. Syncdreamer: Generating multiview-consistent images from a single-view image. arXiv preprint arXiv:2309.03453, 2023.
- Wong L, Grand G, Lew A K, et al. From word models to world models: Translating from natural language to the probabilistic language of thought. arXiv preprint arXiv:2306.12672, 2023.
- Yang T L, Lee K Y, Zhang K, et al. Functional Linear Non-Gaussian Acyclic Model for Causal Discovery. arXiv preprint arXiv:2401.09641, 2024.
- Zhao X, Wang M, Zhao X, et al. Embedding in recommender systems: A survey[J]. arXiv preprint arXiv:2310.18608, 2023


